INTRODUCTION
Information retrieval is a wide, often loosely-defined term but in these pages I shall be concerned only with automatic information retrieval systems. Automatic as opposed to manual and information as opposed to data or fact. Unfortunately the word information can be very misleading. In the context of information retrieval (IR), information, in the technical meaning given in Shannon's theory of communication, is not readily measured (Shannon and Weaver[1]). In fact, in many cases one can adequately describe the kind of retrieval by simply substituting 'document' for 'information'. Nevertheless, 'information retrieval' has become accepted as a description of the kind of work published by Cleverdon, Salton, Sparck Jones, Lancaster and others. A perfectly straightforward definition along these lines is given by Lancaster[2]: 'Information retrieval is the term conventionally, though somewhat inaccurately, applied to the type of activity discussed in this volume. An information retrieval system does not inform (i.e. change the knowledge of) the user on the subject of his inquiry. It merely informs on the existence (or non-existence) and whereabouts of documents relating to his request.' This specifically excludes Question-Answering systems as typified by Winograd[3] and those described by Minsky[4]]. It also excludes data retrieval systems such as used by, say, the stock exchange for on-line quotations.
To make clear the difference between data retrieval (DR) and information retrieval (IR), I have listed in Table 1.1 some of the distinguishing properties of data and information retrieval. One
Table 1.1 DATA RETRIEVAL OR INFORMATION RETRIEVAL?
Data Retrieval (DR) Information Retrieval (IR)
Matching Exact match Partial match, best matchInference Deduction Induction
Model Deterministic Probabilistic
Classification Monothetic Polythetic
Query language Artificial Natural
Query specification Complete Incomplete
Items wanted Matching Relevant
Error response Sensitive Insensitive
may want to criticise this dichotomy on the grounds that the boundary between the two is a vague one. And so it is, but it is a useful one in that it illustrates the range of complexity associated with each mode of retrieval.
Let us now take each item in the table in turn and look at it more closely. In data retrieval we are normally looking for an exact match, that is, we are checking to see whether an item is or is not present in the file. In information retrieval this may sometimes be of interest but more generally we want to find those items which partially match the request and then select from those a few of the best matching ones.
The inference used in data retrieval is of the simple deductive kind, that is, aRb and bRc then aRc. In information retrieval it is far more common to use inductive inference; relations are only specified with a degree of certainty or uncertainty and hence our confidence in the inference is variable. This distinction leads one to describe data retrieval as deterministic but information retrieval as probabilistic. Frequently Bayes' Theorem is invoked to carry out inferences in IR, but in DR probabilities do not enter into the processing.
Another distinction can be made in terms of classifications that are likely to be useful. In DR we are most likely to be interested in a monothetic classification, that is, one with classes defined by objects possessing attributes both necessary and sufficient to belong to a class. In IR such a classification is one the whole not very useful, in fact more often a polythetic classification is what is wanted. In such a classification each individual in a class will possess only a proportion of all the attributes possessed by all the members of that class. Hence no attribute is necessary nor sufficient for membership to a class.
The query language for DR will generally be of the artificial kind, one with restricted syntax and vocabulary, in IR we prefer to use natural language although there are some notable exceptions. In DR the query is generally a complete specification of what is wanted, in IR it is invariably incomplete. This last difference arises partly from the fact that in IR we are searching for relevant documents as opposed to exactly matching items. The extent of the match in IR is assumed to indicate the likelihood of the relevance of that item. One simple consequence of this difference is that DR is more sensitive to error in the sense that, an error in matching will not retrieve the wanted item which implies a total failure of the system. In IR small errors in matching generally do not affect performance of the system significantly.
Many automatic information retrieval systems are experimental. I only make occasional reference to operational systems. Experimental IR is mainly carried on in a 'laboratory' situation whereas operational systems are commercial systems which charge for the service they provide. Naturally the two systems are evaluated differently. The 'real world' IR systems are evaluated in terms of 'user satisfaction' and the price the user is willing to pay for its service. Experimental IR systems are evaluated by comparing the retrieval experiments with standards specially constructed for the purpose. I believe that a book on experimental information retrieval, covering the design and evaluation of retrieval systems from a point of view which is independent of any particular system, will be a great help to other workers in the field and indeed is long overdue.
Many of the techniques I shall discuss will not have proved themselves incontrovertibly superior to all other techniques, but they have promise and their promise will only be realised when they are understood. Information about new techniques has been so scattered through the literature that to find out about them you need to be an expert before you begin to look. I hope that I will be able to take the reader to the point where he will have little trouble in implementing some of the new techniques. Also, that some people will then go on to experiment with them, and generate new, convincing evidence of their efficiency and effectiveness.
My aim throughout has been to give a complete coverage of the more important ideas current in various special areas of information retrieval. Inevitably some ideas have been elaborated at the expense of others. In particular, emphasis is placed on the use of automatic classification techniques and rigorous methods of measurement of effectiveness. On the other hand, automatic content analysis is given only a superficial coverage. The reasons are straightforward, firstly the material reflects my own bias, and secondly, no adequate coverage of the first two topics has been given before whereas automatic content analysis has been documented very well elsewhere. A subsidiary reason for emphasising automatic classification is that little appears to be known or understood about it in the context of IR so that research workers are loath to experiment with it.
The structure of the book
The introduction presents some basic background material, demarcates the subject and discusses loosely some of the problems in IR. The chapters that follow cover topics in the order in which I would think about them were I about to design an experimental IR system. They begin by describing the generation of machine representations for the information, and then move on to an explanation of the logical structures that may be arrived at by clustering. There are numerous methods for representing these structures in the computer, or in other words, there is a choice of file structures to represent the logical structure, so these are outlined next. Once the information has been stored in this way we are able to search it, hence a discussion of search strategies follows. The chapter on probabilistic retrieval is an attempt to create a formal model for certain kinds of search strategies. Lastly, in an experimental situation all of the above will have been futile unless the results of retrieval can be evaluated. Therefore a large chapter is devoted to ways of measuring the effectiveness of retrieval. In the final chapter I have indulged in a little speculation about the possibilities for IR in the next decade.
The two major chapters are those dealing with automatic classification and evaluation. I have tried to write them in such a way that each can be read independently of the rest of the book (although I do not recommend this for the non-specialist).
Outline
Chapter 2: Automatic Text Analysis - contains a straightforward discussion of how the text of a document is represented inside a computer. This is a superficial chapter but I think it is adequate in the context of this book.
Chapter 3: Automatic Classification - looks at automatic classification methods in general and then takes a deeper look at the use of these methods in information retrieval.
Chapter 4: File Structures - here we try and discuss file structures from the point of view of someone primarily interested in information retrieval.
Chapter 5: Search Strategies - gives an account of some search strategies when applied to document collections structured in different ways. It also discusses the use of feedback.
Chapter 6: Probabilistic Retrieval - describes a formal model for enhancing retrieval effectiveness by using sample information about the frequency of occurrence and co-occurrence of index terms in the relevant and non-relevant documents.
Chapter 7: Evaluation - here I give a traditional view of the measurement of effectiveness followed by an explanation of some of the more promising attempts at improving the art. I also attempt to provide foundations for a theory of evaluation.
Chapter 8: The Future - contains some speculation about the future of IR and tries to pinpoint some areas of research where further work is desperately needed.
Information retrieval
Since the 1940s the problem of information storage and retrieval has attracted increasing attention. It is simply stated: we have vast amounts of information to which accurate and speedy access is becoming ever more difficult. One effect of this is that relevant information gets ignored since it is never uncovered, which in turn leads to much duplication of work and effort. With the advent of computers, a great deal of thought has been given to using them to provide rapid and intelligent retrieval systems. In libraries, many of which certainly have an information storage and retrieval problem, some of the more mundane tasks, such as cataloguing and general administration, have successfully been taken over by computers. However, the problem of effective retrieval remains largely unsolved.
In principle, information storage and retrieval is simple. Suppose there is a store of documents and a person (user of the store) formulates a question (request or query) to which the answer is a set of documents satisfying the information need expressed by his question. He can obtain the set by reading all the documents in the store, retaining the relevant documents and discarding all the others. In a sense, this constitutes 'perfect' retrieval. This solution is obviously impracticable. A user either does not have the time or does not wish to spend the time reading the entire document collection, apart from the fact that it may be physically impossible for him to do so.
When high speed computers became available for non-numerical work, many thought that a computer would be able to 'read' an entire document collection to extract the relevant documents. It soon became apparent that using the natural language text of a document not only caused input and storage problems (it still does) but also left unsolved the intellectual problem of characterising the document content. It is conceivable that future hardware developments may make natural language input and storage more feasible. But automatic characterisation in which the software attempts to duplicate the human process of 'reading' is a very sticky problem indeed. More specifically, 'reading' involves attempting to extract information, both syntactic and semantic, from the text and using it to decide whether each document is relevant or not to a particular request. The difficulty is not only knowing how to extract the information but also how to use it to decide relevance. The comparatively slow progress of modern linguistics on the semantic front and the conspicuous failure of machine translation (Bar-Hillel[5]) show that these problems are largely unsolved.
The reader will have noticed that already, the idea of 'relevance' has slipped into the discussion. It is this notion which is at the centre of information retrieval. The purpose of an automatic retrieval strategy is to retrieve all the relevant documents at the same time retrieving as few of the non-relevant as possible. When the characterisation of a document is worked out, it should be such that when the document it represents is relevant to a query, it will enable the document to be retrieved in response to that query. Human indexers have traditionally characterised documents in this way when assigning index terms to documents. The indexer attempts to anticipate the kind of index terms a user would employ to retrieve each document whose content he is about to describe. Implicitly he is constructing queries for which the document is relevant. When the indexing is done automatically it is assumed that by pushing the text of a document or query through the same automatic analysis, the output will be a representation of the content, and if the document is relevant to the query, a computational procedure will show this.
Intellectually it is possible for a human to establish the relevance of a document to a query. For a computer to do this we need to construct a model within which relevance decisions can be quantified. It is interesting to note that most research in information retrieval can be shown to have been concerned with different aspects of such a model.
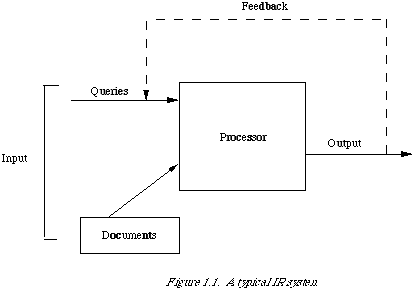
An information retrieval system
Let me illustrate by means of a black box what a typical IR system would look like. The diagram shows three components: input, processor and output. Such a trichotomy may seem a little trite, but the components constitute a convenient set of pegs upon which to hang a discussion.
Starting with the input side of things. The main problem here is to obtain a representation of each document and query suitable for a computer to use. Let me emphasise that most computer-based retrieval systems store only a representation of the document (or query) which means that the text of a document is lost once it has been processed for the purpose of generating its representation. A document representative could, for example, be a list of extracted words considered to be significant. Rather than have the computer process the natural language, an alternative approach is to have an artificial language within which all queries and documents can be formulated. There
is some evidence to show that this can be effective (Barber et al.[6]). Of course it presupposes that a user is willing to be taught to express his information need in the language.
When the retrieval system is on-line, it is possible for the user to change his request during one search session in the light of a sample retrieval, thereby, it is hoped, improving the subsequent retrieval run. Such a procedure is commonly referred to as feedback. An example of a sophisticated on-line retrieval system is the MEDLINE system (McCarn and Leiter[7]). I think it is fair to say that it will be only a short time before all retrieval systems will be on-line.
Secondly, the processor, that part of the retrieval system concerned with the retrieval process. The process may involve structuring the information in some appropriate way, such as classifying it. It will also involve performing the actual retrieval function, that is, executing the search strategy in response to a query. In the diagram, the documents have been placed in a separate box to emphasise the fact that they are not just input but can be used during the retrieval process in such a way that their structure is more correctly seen as part of the retrieval process.
Finally, we come to the output, which is usually a set of citations or document numbers. In an operational system the story ends here. However, in an experimental system it leaves the evaluation to be done.
IR in perspective
This section is not meant to constitute an attempt at an exhaustive and complete account of the historical development of IR. In any case, it would not be able to improve on the accounts given by Cleverdon[8] and Salton[9]]. Although information retrieval can be subdivided in many ways, it seems that there are three main areas of research which between them make up a considerable portion of the subject. They are: content analysis, information structures, and evaluation. Briefly the first is concerned with describing the contents of documents in a form suitable for computer processing; the second with exploiting relationships between documents to improve the efficiency and effectiveness of retrieval strategies; the third with the measurement of the effectiveness of retrieval.
Since the emphasis in this book is on a particular approach to document representation, I shall restrict myself here to a few remarks about its history. I am referring to the approach pioneered by Luhn[10]. He used frequency counts of words in the document text to determine which words were sufficiently significant to represent or characterise the document in the computer (more details about this in the next chapter). Thus a list of what might be called 'keywords' was derived for each document. In addition the frequency of occurrence of these words in the body of the text could also be used to indicate a degree of significance. This provided a simple weighting scheme for the 'keywords' in each list and made available a document representative in the form of a 'weighted keyword description'.
At this point, it may be convenient to elaborate on the use of 'keyword'. It has become common practice in the IR literature to refer to descriptive items extracted from text as keywords or terms. Such items are often the outcome of some process such as, for example, the gathering together of different morphological variants of the same word. In this book, keyword and term will be used interchangeably.
The use of statistical information about distributions of words in documents was further exploited by Maron and Kuhns[11] and Stiles[12] who obtained statistical associations between keywords. These associations provided a basis for the construction of a thesaurus as an aid to retrieval. Much of this early research was brought together with the publication of the 1964 Washington Symposium on Statistical Association Methods for Mechanized Documentation (Stevens et al. [13]).
Sparck Jones has carried on this work using measures of association between keywords based on their frequency of co-occurrence (that is, the frequency with which any two keywords occur together in the same document). She has shown[14] that such related words can be used effectively to improve recall, that is, to increase the proportion of the relevant documents which are retrieved. Interestingly, the early ideas of Luhn are still being developed and many automatic methods of characterisation are based on his early work.
The term information structure (for want of better words) covers specifically a logical organisation of information, such as document representatives, for the purpose of information retrieval. The development in information structures has been fairly recent. The main reason for the slowness of development in this area of information retrieval is that for a long time no one realised that computers would not give an acceptable retrieval time with a large document set unless some logical structure was imposed on it. In fact, owners of large data-bases are still loath to try out new organisation techniques promising faster and better retrieval. The slowness to recognise and adopt new techniques is mainly due to the scantiness of the experimental evidence backing them. The earlier experiments with document retrieval systems usually adopted a serial file organisation which, although it was efficient when a sufficiently large number of queries was processed simultaneously in a batch mode, proved inadequate if each query required a short real time response. The popular organisation to be adopted instead was the inverted file. By some this has been found to be restrictive (Salton[15]). More recently experiments have attempted to demonstrate the superiority of clustered files for on-line retrieval.
The organisation of these files is produced by an automatic classification method. Good[16] and Fairthorne[17] were among the first to suggest that automatic classification might prove useful in document retrieval. Not until several years later were serious experiments carried out in document clustering (Doyle[18]; Rocchio[19]). All experiments so far have been on a small scale. Since clustering only comes into its own when the scale is increased, it is hoped that this book may encourage some large scale experiments by bringing together many of the necessary tools.
Evaluation of retrieval systems has proved extremely difficult. Senko[20] in an excellent survey paper states: 'Without a doubt system evaluation is the most troublesome area in ISR ...', and I am inclined to agree. Despite excellent pioneering work done by Cleverdon et al.[21] in this area, and despite numerous measures of effectiveness that have been proposed (see Robertson[22, 23 ]for a substantial list), a general theory of evaluation had not emerged. I attempt to provide foundations for such a theory in Chapter 7 (page 168).
In the past there has been much debate about the validity of evaluations based on relevance judgments provided by erring human beings. Cuadra and Katter[24]supposed that relevance was measurable on an ordinal scale (one which arises from the operation of rank-ordering) but showed that the position of a document on such a scale was affected by external variables not usually controlled in the laboratory. Lesk and Salton[25] subsequently showed that a dichotomous scale on which a document is either relevant or non-relevant, when subjected to a certain probability of error, did not invalidate the results obtained for evaluation in terms of precision (the proportion of retrieved documents which are relevant) and recall(the proportion of relevant documents retrieved). Today effectiveness of retrieval is still mostly measured in terms of precision and recall or by measures based thereon. There is still no adequate statistical treatment showing how appropriate significance tests may be used (I shall return to this point in the Chapter on Evaluation, page 178). So, after a few decades of research in this area we basically have only precision and recall, and a working hypothesis which states, quoting Cleverdon[26]: 'Within a single system, assuming that a sequence of sub-searches for a particular question is made in the logical order of expected decreasing precision, and the requirements are those stated in the question, there is an inverse relationship between recall and precision, if the results of a number of different searches are averaged.'
Effectiveness and efficiency
Much of the research and development in information retrieval is aimed at improving the effectiveness and efficiency of retrieval. Efficiency is usually measured in terms of the computer resources used such as core, backing store, and C.P.U. time. It is difficult to measure efficiency in a machine independent way. In any case, it should be measured in conjunction with effective-ness to obtain some idea of the benefit in terms of unit cost. In the previous section I mentioned that effectiveness is commonly measured in terms of precision and recall. I repeat here that precision is the ratio of the number of relevant documents retrieved to the total number of documents retrieved, and recall is the ratio of the number of relevant documents retrieved to the total number of relevant documents (both retrieved and not retrieved). The reason for emphasising these two measures is that frequent reference is made to retrieval effectiveness but its detailed discussion is delayed until Chapter 7. It will suffice until we reach that chapter to think of retrieval effectiveness in terms of precision and recall. It would have been possible to give the chapter on evaluation before any of the other material but this, in my view, would have been like putting the cart before the horse. Before we can appreciate the evaluation of observations we need to understand what gave rise to the observations. Hence I have delayed discussing evaluation until some understanding of what makes an information retrieval system tick has been gained. Readers not satisfied with this order can start by first reading Chapter 7 which in any case can be read independently.
Bibliographic remarks
The best introduction to information retrieval is probably got by reading some of the early papers in the field. Luckily many of these have now been collected in book form. I recommend for browsing the books edited by Garvin[27], Kochen[28], Borko[29], Schecter[30 ]and Saracevic[31]. It is also worth noting that some of the papers cited in this book may be found in one of these collections and therefore be readily accessible. A book which is well written and can be read without any mathematical background is one by Lancaster[2]. More recently, a number of books have come out entirely devoted to information retrieval and allied topics, they are Doyle[32], Salton[33], Paice[34], and Kochen[35]. In particular, the latter half of Doyle's book makes interesting reading since it describes what work in IR was like in the early days (the late 1950s to early 1960s). A critical view of information storage and retrieval is presented in the paper by Senko[20]. This paper is more suitable for people with a computer science background, and is particularly worth reading because of its healthy scepticism of the whole subject. Readers more interested in information retrieval in a library context should read Vickery[36].
One early publication worth reading which is rather hard to come by is the report on the Cranfield II project by Cleverdon et al.[21]. This report is not really introductory material but constitutes, in my view, one of the milestones in information retrieval. It is an excellent example of the experimental approach to IR and contains many good ideas which have subsequently been elaborated in the open literature. Time spent on this report is well spent.
Papers on information retrieval have a tendency to get published in journals on computer science and library science. There are, however, a few major journals which are largely devoted to information retrieval. These are, Journal of Documentation, Information Storage and Retrieval*, and Journal of the American Society for Information Science.
Finally, every year a volume in the series Annual Review of Information Science and Technology is edited by C. A. Cuadra. Each volume attempts to cover the new work published in information storage and retrieval for that year. As a source of references to the current literature it is unsurpassed. But they are mainly aimed at the practitioner and as such are a little difficult to read for the uninitiated.
References
1. SHANNON, C.E. and WEAVER, W., The Mathematical Theory of Communication, University of Illinois Press, Urbana (1964).
2. LANCASTER, F.W., Information Retrieval Systems: Characteristics, Testing and Evaluation, Wiley, New York (1968).
3. WINOGRAD, T., Understanding Natural Language, Edinburgh University Press, Edinburgh (1972).
4. MINSKY, M., Semantic Information Processing, MIT Press, Cambridge, Massachusetts (1968).
5. BAR-HILLEL, Y., Language and Information. 'Selected Essays on their Theory and Application, Addison-Wesley, Reading, Massachusetts (1964).
6. BARBER, A.S., BARRACLOUGH, E.D. and GRAY, W.A. 'On-line information retrieval as a scientist's tool', Information Storage and Retrieval, 9, 429-44- (1973).
7. McCARN, D.B. and LEITER, J., 'On-line services in medicine and beyond', Science, 181, 318-324 (1973).
8. CLEVERDON, C.W., 'Progress in documentation. Evaluation of information retrieval systems', Journal of Documentation, 26, 55-67, (1970).
9. SALTON, G., 'Automatic text analysis', Science, 168, 335-343 (1970).
10. LUHN, H.P., 'A statistical approach to mechanised encoding and searching of library information', IBM Journal of Research and Development, 1, 309-317 (1957).
11. MARON, M.E. and KUHNS, J.L., 'On relevance, probabilistic indexing and information retrieval', Journal of the ACM, 7, 216-244 (1960).
12. STILES, H.F., 'The association factor in information retrieval', Journal of the ACM, 8, 271-279 (1961).
13. STEVENS, M.E., GIULIANO, V.E. and HEILPRIN, L.B., Statistical Association Methods for Mechanised Documentation, National Bureau of Standards, Washington (1964).
14. SPARCK JONES, K., Automatic Keyword Classification for Information Retrieval, Butterworths, London (1971).
15. SALTON, G., Paper given at the 1972 NATO Advanced Study Institute for on-line mechanised information retrieval systems (1972).
16. GOOD, I.J., 'Speculations concerning information retrieval', Research Report PC-78, IBM Research Centre, Yorktown Heights, New York (1958).
17. FAIRTHORNE, R.A., 'The mathematics of classification', Towards Information Retrieval, Butterworths, London, 1-10 (1961).
18. DOYLE, L.B., 'Is automatic classification a reasonable application of statistical analysis of text?', Journal of the ACM, 12, 473-489 (1965).
19. ROCCHIO, J.J., 'Document retrieval systems - optimization and evaluation', Ph.D. Thesis, Harvard University. Report ISR-10 to National Science Foundation, Harvard Computation Laboratory (1966).
20. SENKO, M.E., 'Information storage and retrieval systems'. In Advances in Information Systems Science, (Edited by J. Tou) Plenum Press, New York (1969).
21. CLEVERDON, C.W., MILLS, J. and KEEN, M., Factors Determining the Performance of Indexing Systems, Vol. 1, Design, Vol.II, Test Results, ASLIB Cranfield Project, Cranfield (1966).
22. ROBERTSON, S.E., 'The parameter description of retrieval tests', Part 1; The basic parameters, Journal of Documentation, 25, 11-27 (1969).
23. ROBERTSON, S.E., 'The parameter description of retrieval tests', Part 2; Overall measures, Journal of Documentation, 25, 93-107 (1969).
24. CUADRA, A.C. and KATTER, R.V., 'Opening the black box of "relevance"', Journal of Documentation, 23, 291-303 (1967).
25. LESK, M.E. and SALTON, G., 'Relevance assessments and retrieval system evaluation', Information Storage and Retrieval, 4, 343-359 (1969).
26. CLEVERDON, C.W., 'On the inverse relationship of recall and precision', Journal of Documentation, 28, 195-201 (1972).
27. GARVIN, P.L., Natural Language and the Computer, McGraw-Hill, New York (1963).
28. KOCHEN, M., The Growth of Knowledge - Readings on Organisation and Retrieval of Information, Wiley, New York (1967).
29. BORKO, H., Automated Language Processing, Wiley, New York (1967).
30. SCHECTER, G. Information Retrieval: A Critical View, Academic Press, London (1967).
31. SARACEVIC, T., Introduction to Information Science, P.R. Bowker, New York and London (1970).
32. DOYLE, L.B., Information Retrieval and Processing, Melville Publishing Co., Los Angeles, California (1975).
33. SALTON, G., Dynamic Information and Library Processing, Prentice-Hall, Englewoods Cliffs, N.J. (1975).
34. PAICE, C.D., Information Retrieval and the Computer, Macdonald and Jane's, London (1977).
35. KOCHEN, M., Principles of Information Retrieval, Melville Publishing Co., Los Angeles, California (1974).
36. VICKERY, B.C., Techniques of Information Retrieval, Butterworths, London (1970).
 Next Chapter: Automatic Text Analysis
Next Chapter: Automatic Text Analysis
 Back to Preface and Contents
Back to Preface and Contents