Erlang is a functional language with strict evaluation developed by Ericsson. Functional languages make programming easier for us because in functional language (declarative), we more focus on what we need but in imperative language we need clearly specify how it should be implemented.
Functional programming avoids side effects because there is no share memory. Usually in imperative language such as Java and C#, parallel threads control the mutual exclusion by conventional approaches like monitors or semaphores.
But in functional language such as Erlang, parallel processes do not have mutual exclusion because there is no shared resource and it makes easier writing a parallel program in functional language. In Erlang concurrent processes communicate with message passing based on actor model.
In actor modeling each process is an actor and actor can only communicate by sending a copy of resource in a message format. Actor model is a mathematical model of concurrent computation.
Erlang programs can be made from thousands to millions of extremely lightweight processes . Concurrency in Erlang is supported in programming language (and not operating system). Because creating process is done at language level (Erlang Virtual Machine), then it's much more cost-effective. Creating and terminating a new process in Erlang is fast and the scheduling overhead is low with a small memory footprint.
Erlang has some important features that made it worth to learn. If you need to write programs that run faster on a multicore computer Erlang is a proper choice. Erlang is a Concurrency Oriented Programming Language (COPL) and processes are the primary components that construct an Erlang application. Erlang supports symmetric multiprocessing (SMP) computer hardware architecture.
Another important feature of Erlang is fault-tolerant. Erlang makes it easy to monitor all processes and when one of them crash try to restart that part of the system without needing to bring the whole thing down. A supervisor process is monitoring how different parts of the application behave.
Many large-scale industrial products are written in Erlang. For example some users of Erlang are : Motorola, T-Mobile, Amazon, Yahoo, Facebook. During these years valuable modules, frameworks and applications have been developed in Erlang such as OTP (Open Telecom Platform), open-source libraries such as XML processing , database systems such as Riak and high-quality tools such as testing frameworks and debuggers.
Hot code replacement is an essential feature for a real-time system. In real-time systems we do not want to stop the system in order to upgrade the code. In real system (For example X2000 satellite control system developed by NASA) dynamic code upgrade should be supported. Erlang provides an easy to use mechanism to hot swapping.
Erlang programs can be run on a network of processors. Networks of computers are unlimited and provides an environment for distributed Erlang systems. A distributed system can be consists of a number of Erlang runtime systems (nodes) communicating with each other.
The last released version of Erlang can be download from here. For windows operating system download the Windows Binary File. Also source code is available in download page for linux OS. After installation, for running the Erlang in Windows, you can go to the installation folder and run erl.exe in command line or run shell window by clicking the werl.exe file.
After running Erlang shell, the first expression that you can run is 2+2.
For shutdown the Erlang, just type:
q(). is equivalent to call function stop from module init
For running an Erlang function from command line without shell you can use the following:
-s init stop is equivalent to init:stop()
Number: Contains integers and floats. General format is base#value. Default value for base is 10.
16#2b. means 43 in decimal
Atoms: A constant with name. They should be enclosed in single quote (') if it does not begin with a lower-case letter or if it contains other characters than alphanumeric characters, underscore (_), or @.
natural_food
'Name' in quotes because it begin with upper-case letter
'student id' in quotes because it contains space
Booleans: Atoms true and false are used to denote Boolean values. Four boolean expressions are not, or, and,xor :
(1 > 5) or (4 > 1).
true xor false.
Tuples: Store collection of elements. Elements data type can be different but number of elements are fix. General format of tuple is:
Size of tuple is equal to number of elements in the tuple.
Lists: store collections of elements. Lists in Erlang are very useful. It's the most used data structure. They are denoted by square brackets and elements are separated by comma [Element1,...,ElementN].
Elements in lists can be of different data type. [] means an empty list. A list can have two forms:
1) Empty list[]
2)[Head|Tail] that Head is the first element of list and Tail is the remaining items of list.
A recursive definition of a list is shown below:
Example of recursive presentation of [a,b,c] is :
[a|[b|[c|[]]]]
Variables in Erlang are dynamically typed then there is no compile time type checking (Except haskell that is statically typed. For example adding a string with integer raise error at compile time). A variable in erlang has two states:
- Bound: It is bound a value then cannot be modified.
- Unbound: It can be bound to a value of any types at any time but only once in their life. After binding, their state changes to Bound.
Variables must start with an uppercase letter or underscore (_). It may contain alphanumeric characters, underscore and @.
Anonymous variables are denoted by underscore (_) and can be used as a wildcard symbol in pattern matching.
If a variable is started with underscore, it is not anonymous but the are useful because compiler dose not generate any warnings when it is unused. For example in following example compiler generate warning because variable A is unused:
But in following example because variable _A started with (_) warning will not be generated:
| Comparisons operators | Description |
| == | equal to |
| /= | not equal to |
| =< | less than or equal to |
| < | less than |
| >= | greater than or equal to |
| > | greater than |
| =:= | exactly equal to |
| =/= | exactly not equal to |
2> 1=:=1.0.
Erlang is functional language. Functional languages are based on function and functions play an important role in functional programming languages. A function consists of clauses. Clauses are separated by a semicolon, and the final clause is terminated by dot. For example in math function there are four clause and each clause is ended by ; except the last one that ended by .
math(Operator,A,B) when Operator == subtract -> A-B;
math(Operator,A,B) when Operator == multiple -> A*B;
math(Operator,A,B) when Operator == division -> A div B.
when keyword is used in the heads of function as a guard. For above example the first clause matches when Operator is equal to add. If the first clause doesn't match, then the second clause is tried.
How we can run the function? For running a function we need to put them in modules. For more info read modules section.
Anonymous functions have no name. They are defined between fun ... end. We can define an anonymous function and assign it to a variable:
Inc(1).
If we need to have an anonymous function that increase by one when the input number is less than 100, decrease by one when the input number is greater than 100, then we can write it as follow:
(X) when X>100 -> X-1
(100) ->100 end.
This example shows that fun does not appear before each expression.
Higher-order functions are functions that return functions or accept functions as their arity. For example lists:filter get a boolean function and a list as parameters and return a new sublist that function return true after apply on them.
lists:map(Odd, [1,2,3,4,5,6,8,9]).
In following example a function is defined that return a function:
Fun=Increment(5).
Fun(4).
In previous example, function Increment returns a function as a result. We put the result of Increment function in a variable and then call it.
There are some useful built-in higher-order functions in lists module.
BIFs are built-in Erlang's functions. They are belong to the module erlang and they are auto-imported. A complete list of BIFs are listed here.
Erlang programs consist of functions that are grouped and defined within modules. Modules are stored in files with .erl extensions. Before using modules we must compile them. A compiled module has the extension beam. At the first stage you need to define your function in module. You need to create a file with erl extention. In next stage you need define your function in created file as follow:
-export([math/3]).
math(Operator,A,B) when Operator == add -> A+B;
math(Operator,A,B) when Operator == subtract -> A-B;
math(Operator,A,B) when Operator == multiple -> A*B;
math(Operator,A,B) when Operator == division -> A div B.
By using -module annotation we can give a name to our module. -export annotation indicates every functions that is accessible form outside of module. If a function does not be included in -export annotation then it is not accessible outside the module and only can be called inside the module by other functions. In Erlang function's parameters are named arity. Export notation also specifies the number of function's arity.
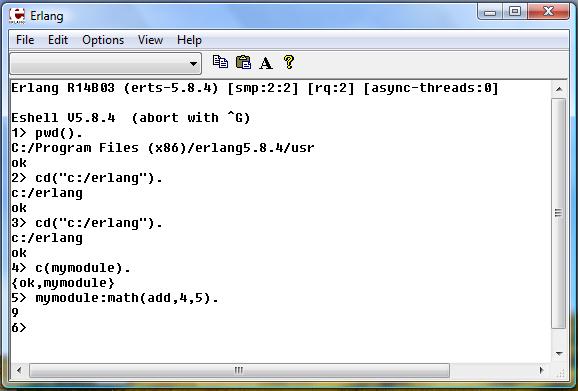
For running the function we need to compile our module. For compile we need first go to the folder that our module file is located.
For changing the current directory inside the shell we can use cd("a valid path"). For example if our module is located
at c:\erlang we can use cd("C:/erlang"). command to change our current directory. To find the current working directory pwd(). command can be used.
For compile we should use command c(mymodule). but you must be sure that in your current directory module file is located.
After compiling the module, for running a specific function we must call it as following general format:
mudulename:functionname(A,B,...).
For example for calling our defined function :
Following picture depicts how use cd to change the current path. It also shows how to compile and run the mymodule module.
List comprehensions let us to build a list based on some rules without applying any function. Using this technique make our program easier and shorter. General format of list comprehensions is like:
For example for generate a list of double value of even number between 1 to 20 :
Remembering the position of elements in tube make it difficult to use specially for large data structure. Records provide a name for accessing to each element in a tuple. For example for defining a student structure :
For example, the below code makes all records in the file student.hrl accessible through the shell:
For getting an instance of defined record:
To access to the record element:
General format of case is as follow:
Pattern1 [when GuardSeq1] -> Body1;
...;
PatternN [when GuardSeqN] -> BodyN
end
Implementing filter function by using case:
case P(H) of
true -> [H|filter(P, T)];
false -> filter(P, T)
end;
filter(P, []) ->[].
General format of if is as follow:
GuardSeq1 ->
Body1;
...;
GuardSeqN ->
BodyN
end
Implementing filter function by using if:
Result=P(H),
if
(Result==true) -> [H|filter(P, T)];
true -> filter(P, T)
end;
filter(P, []) ->[].
Exceptions(run-time error) are raised due to one of these reasons: internal errors or by calling explicitly in code throw(Exception), exit(Exception) or erlang:error(Exception).
Explicitly generate an error
exit(Reason): End the execution in the current process. It generate a stack trace that helps to find the location of the exception.
erlang:error(Reason): error are pretty similar to exit. The only difference is when we use exit, a message {'EXIT',PID,Reason} will be broadcast to all processes that are linked to the current process. This message usage will be discussed in the next section. Moreover internal errors of Erlang runtime system are error.
throw(Reason): throw is used when we expected an error can be handled by programmers. For example when user does not have a permission to do an action we do not want application completely collapsed. In this case we can use throw to raise an exception that shows permission is needed. Programmer(user of our function) can handle the raised exception by using try .. catch expression.
How handle exception?
There are two general forms of try expression as below:
catch
[Class1:]ExceptionPattern1 [when ExceptionGuardSeq1] ->
ExceptionBody1;
[ClassN:]ExceptionPatternN [when ExceptionGuardSeqN] ->
ExceptionBodyN
end
The try expression can have an of section:
Pattern1 [when GuardSeq1] ->
Body1;
...;
PatternN [when GuardSeqN] ->
BodyN
catch
[Class1:]ExceptionPattern1 [when ExceptionGuardSeq1] ->
ExceptionBody1;
...;
[ClassN:]ExceptionPatternN [when ExceptionGuardSeqN] ->
ExceptionBodyN
end
In following example all kind of exception is handled:
try a_sample_expression() of
Val -> {'No exception :)',Val}
catch
throw:Reason ->{throw, Reason};
error:Reason -> {error, Reason};
exit:Reason -> {exit, Reason};
_:_ -> {this_never_happened}
end.
For tracing the stack in exception we can call get_stacktrace():
get_stacktrace() return a list of tuple that each tuple has two elements: first element of each tuple shows module name and second element shows function that error occurred. List shows all functions that are in stack when error occurred.
General binary format in erlang :
For example look at following example:
The Result's value is :
Why? because 258 can't be located in one byte then there is no space to hold the highest bit(100000010)
Solution? For keeping 258 we need 9 bit then we can ask erlang to assign 9 bit for C:
A=3, B=19, C=258, Result= <<A, B,C:9>>.
We used f(). to unbound all variable to avoid getting error. One useful BIF is term_to_binary(Term) -> Bin that convert erlang's term to binary format. This can be used to serialized erlang terms into binary file, or transfer on network and reconstruct later.
Var=12,term_to_binary(Var). % convert variable to binary
term_to_binary({1,a}). % convert tuple to binary
Another example to show bit syntax in Erlang. We want to show three digits in two bytes(16 bit). We need 3 bit for number 9 , 5 bit for number 19 and 8 bit for number 145 :
A=9, B=19, C=145, Result= <<A:2, B:5,C:8>>.
Usually at the beginning of a module, there is a list of attributes. Attribute format is -attributename(Value). Attribute can be recognize by - sign in front of the attribute name. Some attributes are discussed below:
-module(Module). is mandatory and must be placed at the first of module to show module's name. he name Module, an atom, should be the same as the file name minus the extension erl.
-export(List of functions). Specifies the functions that are visible outside the module.
-import(Module,Functions). Imported functions can be called the same way as local functions, without any module prefix.
-vsn(Vsn). Specifies module version.
-behaviour(Behaviour). Specifies that the module is a callback module for a behaviour. Behaviour can be a user defined behaviour or one of the OTP standard behaviours such as gen_server (client-server model), gen_fsm (finite state machines), gen_event (event handling model), supervisor (supervision tree) or application (a component that can be started and stopped as a reusable unit).
-record(RecordName,Fields). is used by for record definitions.
-include("SomeFile.hrl"). is used by the preprocessor to supports file inclusion. Included files usually contain record definitions. When we use inclusion, the contents of the file are included as-is, at the position of the directive. It is recommended that the included file has extension .hrl .
-define(Macro,Replacement). is used by the preprocessor to supports macros to have more readable programs. It can be used to have a conditional compilation. It is recommended that If a macro is used in several modules, it's definition is placed in an include file.
A macro definition example:
For using macro:
List of predefined macros:
- ?MODULE: The name of the current module.
- ?FILE: The file name of the current module.
- ?LINE: The current line number.
- ?MACHINE: The machine name.
List of macro directives for conditional compilation:
- -undef(Macro).
- -ifdef(Macro).
- -ifndef(Macro).
- -else.
- -endif.
-export([test/0]). -ifdef(debug).
-define(checkDebug, true).
-else.
-define(checkDebug, false).
-endif.
test()->?checkDebug.
directive:test().
Concurrency made it possible to handle several threads of execution at the same time. In erlang we use process instead of thread because threads use share memory but process does not used share data. In erlang the BIF spawn is used to create a new process. General format of spawn is:
For example in following example when we run seq function first hello is three times printed and then goodbye is printed three times. But when par is called both of hello and goodbye are printed but not in a specific order(it is depend on Erlang VM task scheduler)
-export([seq/0, par/0, say_something/2]).
say_something(_What, 0) -> done;
say_something(What, Times) -> io:format("~p~n", [What]), say_something(What, Times - 1).
par() -> FirstPid=spawn(?MODULE, say_something, [hello, 3]),
SecondPid=spawn(?MODULE, say_something, [goodbye, 3]),
io:format("~p~n", [FirstPid]),
io:format("~p~n", [SecondPid]).
seq() -> say_something(hello,3), say_something(goodbye,3).
As showed in this example, spawn return a process identifier(pid). The pid can be used in message passing between process.
For sending a message to another process we need to use sender operator !. For sending message we also need the process identifier(pid) of destination process. Sending a message is asynchronous. It means sender does not wait to get a feedback. Each process has its own message queue for received messages.
Operator "!" is used to send messages. The syntax of "!" is:
When a message arrives at the destination, the process tries to use pattern matching to use it. Receiving construct is used to wait for a messages. It has the format:
pattern1 -> actions1;
pattern2 -> actions2;
....
patternN -> actionsN
end.
In following example we show how message passing can be used by an infinite loop:
-export([loop/0]).
loop() ->
receive
{add, A, B} ->
io:format("Add result is ~p~n" ,[A+B]),
loop
{mul, A, B} ->
io:format("Multiplication result is ~p~n" , [A * B]),
loop();
{minus, A, B} ->
io:format("Minus result is ~p~n" , [A - B
loop();
{division, A, B} ->
io:format("Division result is ~p~n" , [A / B]),
loop();
Other ->
io:format("Operator ~p is not recognised~n" ,[Other]),
loop()
end.
In this example a process in waiting to receive a message. Massage that are match with defined pattern (a tuple) are accepted and processed otherwise an appropriated message is displayed. For testing the example in shell we try to create a process by using spawn at first. after getting pid of new process, we sent a message to it:
Pid = spawn(message,loop,[]).
Pid!{mul,2,4}.
In this example we can name the loop function as a server and anyone that use it call client. In previous example client was Erlang shell. But if client was another process how could it get the result from server? It is obvious that client should send it's identifier to server for getting reply.
-export([loop/0,client/2]).
loop() ->
receive
{From,{add, A, B}} ->
From!A+B,
loop();
{From,{mul, A, B}} ->
From!A*B,
loop();
{From,{minus, A, B}}
From!A-B,
loop();
{From,{division, A, B}} ->
From!A/B,
loop();
_Other ->
loop()
end.
client(Pid,Request)->
Pid ! {self(), Request},
receive
Response ->io:format("Response is ~p~n" ,[Response])
end.
Client send it's pid to server for getting reply. Client find it's pid by using BIF self(). Then server after doing client request send the response to it's pid. This model that is very common in Erlang application is Client-Server model.
To avoid an infinite wait for a message we can use after. In this case we can specify a timeout for waiting. By using this feature we can implement following function:
receive
after T -> true
end.
Also we can write a function that clear the content of process's mailbox:
receive
_Any -> flush_buffer()
after 0 -> true
end.
Why using atom infinity as a value for timeout? It can be used when timeout value is calculated at run-time. For example in some condition maybe we need to wait forever.
Erlang provides a mechanism to assign name to a process and we are able to use these names instead of pid. This is done by using BIF register(atom_name, Pid)
registered_name!hello.
For unassigning a name, we can use unregister(Pid). Getting the list of all registered processes is possible by using registered(). Also whereis(Name) return the Pid that is associated with the Name.
In tail recursive function, there is nothing to do after the function returns. So, there is no need to save the stack frame and instead of a deep stack, the current stack frame is reused. Using tail recursive function in Erlang is important because we need to have some function that loop forever and in this situation we must try to reuse the current stack frame. For example is previous example function loop calls recursively itself forever, thus the function must be tail recursive to avoid stack overflows error. In the following examples we can see the both cases. In the tailsum function, after calling recursively we do not need to come back to this point to use the result of function but in the non_tailsum function caller need the result of callee.
non_tailsum(N)-> N+ non_tailsum(N-1).
tailsum(N)->helper(N,0).
helper(0,Accumulator)->Accumulator;
helper(N,Accumulator)->helper(N-1,Accumulator+N).
In the non_tailsum function, each level of recursion need a deeper level of stack for completing the result. But in the tailsum function by using accumulator and a helper function each level finish his job before going to a deeper level.
Hot swapping code means upgrading the executed code dynamically without stopping the service that use it. This feature is a wonderful service of Erlang that originally inspired by Smalltalk. Fully qualified function call means when we call a function from the current module, we use a complete name for the function (module:function). For calling a function from outside the current module, we always use fully qualified name. If we change the source code of a module and compile it again, the new code will be loaded automatically. Thus, calling a full qualified function refers to the new code, but calling a none qualified function refers to the old code.
For understanding how erlang is reputed for its fault tolerance feature, we need to know about concepts such as link and signal.
Two processes Pid1 and Pid2 can be linked to each other if Pid1 calls the BIF link(Pid2) (or vice versa). Other way to link two processes is using the spawn_link BIFs. When we call spawn_link, both of spawns and links are defined in a single operation. Links are bidirectional which means when two processes are linked if one of them dies, an exit signal is sent to the other one. The process which gets the exit signal also will die. If process wants to be alive, it should trap the exit signal.
Following example traps the exit signal by using process_flag(trap_exit, true) and print the reason of exit signal:
-export([start/1,worker/0,monitor/1]).
monitor(Pid) ->
process_flag(trap_exit, true),
link(Pid),
receive
{'EXIT', Pid, Why} ->
io:format(" process ~p died because of ~p~n",[Pid, Why])
end.
worker()->
receive
error -> error(internal_error);
exit -> exit(internal_exit);
throw -> throw(internal_exit);
Other -> Other
end.
start(Input)->Pid=spawn(?MODULE, worker,[]),
spawn(?MODULE, monitor,[Pid]),
sleep(1000),
Pid!Input.
sleep(T) -> receive
after T -> true
end.
Sleep is used to be sure that monitor process is run. Worker process can be terminated by start argument. If start argument is one of error, exit, throw then worker will die by getting an exception and propagating the corresponding exception signal. Otherwise, worker will die normally and in this case also exit signal is sent for monitor but it is an atom normal. For testing the example please follow as shown below:
link:start(error).
link:start(throw).
link:start(exit).
link:start(anything_else).
We can directly send an exit signal to a process by using exit(Pid, Why).
Monitor is an alternative for link. If process Pid1 create a monitor for Pid2 by calling the BIF erlang:monitor(process, Pid2) then if Pid2 terminates with an exit reason (Reason), a 'DOWN' message is sent to Pid1 as below:
Monitor is unidirectional and this is the main difference between monitor and link. The erlang:monitor function returns a reference which can be used later to remove the monitor link.
In an Erlang distributed program, process communicate through message passing over a network. Distributed programs improve the performance by using other computers' computational resources. They are more reliable because when we have a networks of computer and if one of them fails, other computers can cover it's absence. Distributed program also are scalable because they can be easily scale by adding more computers to the network. Each Erlang node is an Erlang runtime systems. Erlang nodes can be located on the same machine(host) or on the different hosts. For converting an Erlang node to a distributed Erlang node we must give it a name. For finding the name the current node, you can call node() function. Name of each node can be assigned to it when you run the Erlang runtime system on it. For giving a complete name, flag -name (long names) should be used and for short name flag -sname (short names).
erl -name nodename
werl -sname nodename
werl -name nodename
Security in distributed erlang is implemented by cookie. Each node has its own cookie. Cookies are Erlang atom. If two node have the same cookie, they are allowed to communicate. Cookie is configurable by a file which is named $HOME/.erlang.cookie. Cookie also can be set by -setcookie flag as shown follow:
Moreover, there is a BIF erlang:set_cookie(node(), cookie) for setting the cookie on a node.
Hidden nodes are not connected to the other nodes automatically and we need to ask explicitly to set up a connections, whenever it is necessary.
| Distribution Command Line Flags | Description |
| -connect_all false | Avoid implicit transitive connection |
| -hidden | Makes a node into a hidden node |
| -name Name | Set long node names. |
| -setcookie Cookie | Set a cookie for current node as same as erlang:set_cookie(node(), Cookie). |
| -sname Name | Set short node names. |
There are some BIFs that can be used in distributed system:
| Distribution BIFs | Description |
| erlang:disconnect_node(Node) | disconnect the node |
| erlang:get_cookie() | Returns the cookie of the current node. |
| is_alive() | Return true if node can connect to other nodes |
| node() | Returns the name of the current node. |
| nodes() | Returns the other nodes that the current node is connected to them. |
| set_cookie(Node, Cookie) | Set the cookie for current nodes. |
| spawn(Node, Fun) | Creates a process at a remote node. spawn(Fun) create a process on the current node. |
| spawn(Node, Module, FunctionName, Args) | Creates a process at a remote node. |
| spawn_link(Node, Fun) | Exactly like spawn_link(Fun) but on remote node. |
| spawn_link(Node, Mod, Func, ArgList) | Exactly like spawn(Mod, Func, ArgList), but on remote node. |
| monitor_node(Node, true|false) | Monitor the Node and a message{nodedown, Node} is received if the connection is lost or if Node goes down. |
For executing a function on the other nodes, moreover using BIFs distributed functions ( such as spawn, spawn_link), we can use call method from rpc module.
For running two processes on the different hosts, we use -name flag instead of -sname flag. In addition, on different machine we need to set an identical cookie for the nodes:
To add capability for running the previous example on different nodes, you can change it as follow:
-export([start_server/1,client/2]).
start_server(Node) -> spawn(Node,message, loop, []).
loop() ->
receive
{From,{add, A, B}} ->
From!A+B,
loop();
{From,{mul, A, B}} ->
From!A*B,
loop();
{From,{minus, A, B}}
From!A-B,
loop();
{From,{division, A, B}} ->
From!A/B,
loop();
_Other ->
loop()
end.
client(Pid,Request)->
Pid ! {self(), Request},
receive
Response ->io:format("Response is ~p~n" ,[Response])
end.
For running two individual nodes, you need to run them as follow:
erl -name machine2 -setcookie testremote
% both of the below commands run on machin1.
Pid = message:start_server('machine2').
message:client(Pid,{add,3,7}).
In this example, we run start_server function from machine1 on machine2 and then run client function on machin1 to call a service from machine2. Because our processes run on different machines, we assign different names to them. Cookies are the same for the both.
For remote spawn spawn(Node, Module, Function, Parameters) is used.
Erlang Term Storage(ETS) is used to storage a large amount of data as a Erlang terms. All kind of ETS table provide a constant lookup time because of using hash table(except ordered_set that it's access time is logarithmic because of using binary tree). ETS can be shared between processes in an efficient way. Data is organized in ETS as tuples. ETS will be destroyed when the owner process terminates. There are four types of ETS table.
- set
- ordered_set
- bag
- duplicate_bag
In set and ordered_set key is unique for each record. But in bag and duplicate_bag key is not unique for each record. The number of tables stored at one Erlang node is configurable. The default value is 1400 tables and It can be set by environment variable ERL_MAX_ETS_TABLES.
Table can be destroyed explicitly by owner process with using delete(table_identifier) function.
Basic operation about table are:
-
Create table: For creating a new table we can use ets:new(TableName, Options) function. It returns an identifier which can be used in subsequent operations. Identifier can help us to shared a table between different processes within a node.
Options is a list of atoms which specifies table's attributes. If you leave options an empty list, the default values are used.
The first option specifies table type. Table type can be one of these choices: set, ordered_set, bag or duplicate_bag. Default table type is set.
The second option specifies access type. Access can be public, protected or private. All process can read and write to a public table. Only owner process can write in a protected table. Only the owner process can read or write to a private table. Default value of access type is protected.
The third option is table name that cab be used instead of table identifier.
The next option is key position that specifies which element in the stored tuples should be used as key.
Following example create a ordered_set table with a public access. Then delete it.Id = ets:new(myTable, [ordered_set, public]).
ets:delete(Id). -
Insert: General format is ets:insert(Table_Identified, {data1,data2,...}). If table type is set or ordered_set and key of the inserted objects is exist in table the old object is replaced.
TableId=ets:new(programmer,[]).
ets:insert(TableId, {1,amir}).
ets:insert(TableId, {2,david}). -
Delete: For deleting the entire a table the general format is ets:delete(Table_Identified). For deleting all objects with a specific key from a table we can use ets:delete(Table_Identified,Key)..
ets:delete(TableId, 1).
ets:delete(TableId).
-
Lookup: Returns a list of objects with a specific key. ets:lookup(TableId,Key). For example for search in previous example:
ets:lookup(TableId,2).
-
Iterate on table: For traversing over the data in a table there are some functions.
ets:first(TableId) returns the first key in the table. If the table is empty the atom '$end_of_table' will be returned.
Function ets:next(TableId, Key1) returns the next key following Key1 in the table. If there is no next key, the atom '$end_of_table' is returned.
Function ets:prev(TableId, Key1) returns the previous key preceding Key1. If there is no previous key, the atom '$end_of_table' is returned.
ets:last(TableId) returns the last key. If the table is empty the atom '$end_of_table' will be returned.
TableId=ets:new(programmer,[]).
ets:insert(TableId, {1,amir}).
ets:insert(TableId, {2,david}).
ets:insert(TableId, {3,stiven}).
ets:first(Id).
ets:next(Id,2).
ets:prev(Id,3).
ets:last(Id).
Disk Based Term Storage(DETS) provides a term storage on file. The size of Dets files cannot exceed 2 GB. For more file size you can use Mnesia's table fragmentation. Dets tables are one of the following types:
- Set: Key is unique for each record.
- Bag: key is not unique for each record.
- Duplicate_bag: key is not unique for each record.
In compare to ETS table, Dets tables are much slower because in Dets operation involves a series of disk seeks but ETS are kept in RAM.
A Dets table must be opened before any operation and it must be closed finally. For openning a table, dets:open_file(TableName, Options) can be used. First argument specifies the table name that will be used in subsequent operations on the table. The second argument (Option) is a list of {Key, Val} tuples. You can find a complete list of options here
The following example shows how to open a file and write in it and finally close it.
For inserting data into a Dets table, we can use insert(TableName, Objects) or insert_new(TableName, Objects). Function insert replaces an existing key but function insert_new returns false when the key exists in the table.
dets:insert(testTable, {2, david}).
To seatch for a specific key, dets:lookup(TableName, Key) is used as shown below:
dets:lookup(testTable, 2).
Finally, to close a table dets:close(TableName). is called. Only processes that have opened a table are allowed to close it.
- Replicating table at many nodes to provide fault-tolerance
- Arbitrary size and structure for records
- Atomic transactions
- Realtime key/value lookup
- High fault tolerance
- Mnesia's Schemaless feature provides a runtime manipulating schema
Since Mnesia uses Dets tables, there is a limitation on the size of a table in Mnesia (the upper limit of a Dets table is 2 GB). Mnesia's tables can be kept in RAM or on disk.
For creating a distributed database, we need to run more than one erlang node. For example, in the following example, we run two erlang nodes on the same machine(amir-PC).
From command line, run two erlang node(node1, node2)werl -sname node2 -setcookie cookiename
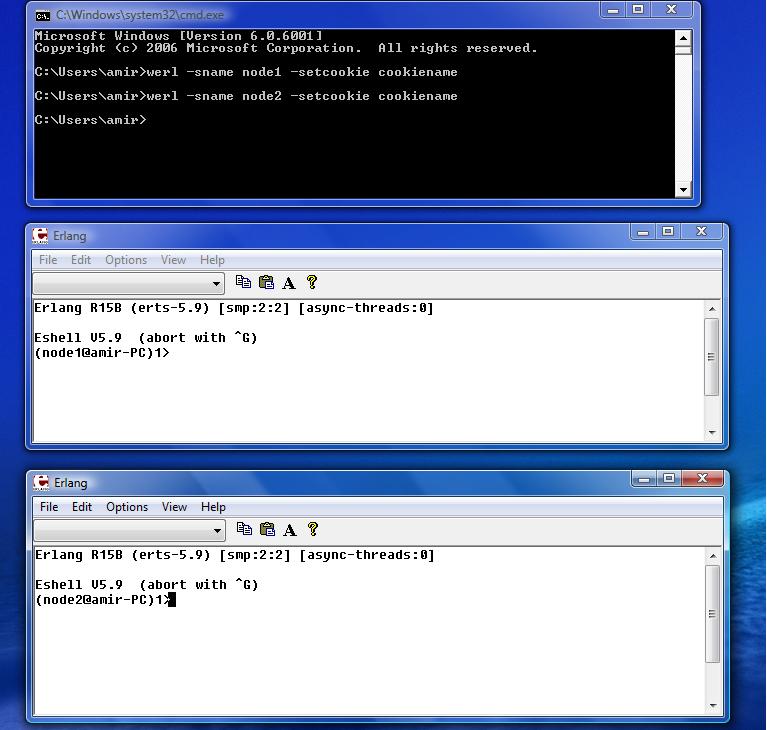
Now for connecting the two nodes to each other, I use net_adm:ping as shown below( note that you must replace your computer name with amir-PC):
I run it on node1. Now two erlang nodes are connected and I check the connection between nodes by nodes() function.

Mnesia database can resides in RAM. In this case, stored information are not persistent and tables need to be created after restarting the system. If you want to have a disc-less database on a specific node, you do not need to create schema directory for that particular node.
But for Creating a persistent database (on disc) on a node, you need to create a local Mnesia directory on that node to store files.
For creating persistent database nodes, mnesia:create_schema(List_Of_Nodes) function can be used. In the following example, a directory structure is created on the local node and all the other connected nodes:
For example after running this code on my computer, because both of erlang nodes are on the same machine, two directories with the following names are created in my home directory:
Mnesia.node2@amir-PC
You can change the default name of directory (Mnesia) by specifying dir directive:
If your db is not distributed and it is located only on one node, do as follow:
After creating your schema, application:start(mnesia) is used to start the Mnesia up on the node.
To displayed information about the status of the database on the node, use function mnesia:info().
For creating a table in mnesia, use function mnesia:create_table(NameOfTable, ListOfTableDefinition). First parameter is the name of table and the second parameter is a list of tuples of the format {key,value}. By using ListOfTableDefinition, you can specify the following features:
- {access_mode, Atom}: Access mode to the table
-
{attributes, AtomList}: A list of attribute names of the table (to avoid hard code any attribute name, use record_info(fields, RecordName) instead).
Note: First element of the attribute list is key. - {index, ListOfAttribute}, A list of attribute names (atoms) or record fields for building extra index table.
- {disc_copies, Nodelist}: A list of the nodes where the table is disc copies.(Also replicas are stored in RAM)
- {disc_only_copies, Nodelist}: A list of the nodes where this table is supposed to have only disc copies (the contents of the replica is not reside in RAM, and then are slower).
- {ram_copies, Nodelist}: A list of the nodes where tables are only RAM copies.
- {record_name, Name}: All records that stored in the table must have this name. Its default value is the same as the name of the table.
- {type, Type}: Type must be one of the atoms set, ordered_set or bag. The default value is set in which all records have unique key.
A complete list of options are listed here.
In the following example, a table (student) is created with four attributes(id,fname,lname,age). Type of table is set and its index is id.
But to avoid hard coding the attribute's name, it is better at first we put record definition in a file (for example student.hrl) as shown below:
Function mnesia:delete_table(TableName) is used to delete a table:
Now I can create table by using record_info function. Note before using disc_copies, you have to create a schema (if you haven't created it yet).
mnesia:start().
mnesia:create_table(student, [{disc_copies, [node()]},{type, set}, {attributes,record_info(fields, student)},{index,[fname]}]).
Transactions are used to avoid race condition in a concurrent environment. It also guarantees a consistent state by providing atomic changes across all nodes in a distributed environment. The code inside a transaction can consist of a series of table manipulation functions. A wrong inside the transaction causes entire transaction to be aborted.
For calling a function as a transaction, use
mnesia:transaction(FunctionName)
To insert into a table, use function mnesia:write(Record) as shown below:
mnesia:transaction(fun() ->mnesia:write(S1) end).
Firstly, we create an instance of student record(S1). Method write is put inside the scope of a transaction. All synchronization for distributed data across multiple nodes is handled by the transaction handler.
Function mnesia:read({TableName, KeyValue}) is used to retrieve information for a specific key:
To read based on index fields, use function index_read(TableName,Value, FieldName):
It is possible to manipulate a table without using transactions. A dirty operation can be used if it is possible for the database to be left in an inconsistent state. Dirty operations are considerably faster (more than 10 times) because transaction manager is not involved to set locks. It can be used as shown below:

