SUPPORTING THE ANALYSIS OF HUMAN ERROR IN NATIONAL AND INTERNATIONAL INCIDENT REPORTING SCHEMES
Chris JOHNSON and Peter McELROY
Department of Computing Science,
University of Glasgow, Glasgow G12 8QQ. Scotland.
johnson@dcs.gla.ac.uk, http://www.dcs.gla.ac.uk/~johnsonABSTRACT
The perceived success of the FAA/NASA’s Aviation Safety Reporting System (ASRS) has led a number of organisations to develop a range of international incident reporting schemes. This paper discusses the consequences of such initiatives. There is a danger that such large-scale systems will become victims of their own success. The ASRS now has almost half a million reports. It is, therefore, important to identify the "core" technologies that support the storage and retrieval of information about human error within such large bodies of incident data. In particular, we show how the Inquery information retrieval engine and the US Navy’s NaCoDAE case-based reasoning system can help to identify common causes, mitigating factors and consequences in a national reporting scheme. This paper goes on to argue that human error analysis techniques must guide the application of these innovative technologies if we are to identify common features amongst thousands of incident reports.
KEYWORDS
Human error, incident reporting, information retrieval, case based reasoning.
1. Introduction
There are many reasons why commercial and regulatory organisations have turned to incident reporting schemes as a primary means of improving the safety of production processes. Near-miss incidents are more frequent than more "serious" accidents. Incident reports are, therefore, amenable to statistical analysis in a way that accident reports are not (van der Schaaf, 1996). Reason (1998) also argues that incident reporting systems help to keep operators focussed on safety issues. By submitting incident reports and by receiving feedback about the improvements based on those reports, it is possible to raise awareness about the potential for failure in the workplace. It can also be argued that these schemes are significantly cheaper to maintain than the costs that can be incurred in the aftermath of a major accident (Hale, Wilpert and Freitag, 1997).
2. From Local to International Schemes
Many incident reporting systems have been set up through local rather than national initiatives. They depend upon the motivation and enthusiasm of key individuals who both sponsor the system and guard the confidentiality of participants (Busse and Johnson, 1999). Partly as a result of this, most previous research has focussed upon techniques that can be used to analyse accounts of human error in relatively small numbers of incident reports (Johnson, 1999). There are important ethical and pragmatic limitations with these local schemes. For example, previous work in the UK health sector has revealed repeated instances in which the same problems were being reported in different hospitals (Johnson, 2000). As a result, lessons, which have already been learnt in one institution, are not being effectively passed onto other similar institutions. It can also be argued that equipment manufacturers and pharmaceutical companies would react more readily if incidents in one hospital were validated by reports from other hospitals throughout the country.
Unfortunately, the bottom-up growth in incident reporting schemes has led to a proliferation both in the forms that are being used to elicit reports and in the techniques that are being applied to analyse those reports. This has the knock-on effect that there are no consistent formats that can be used to transfer report data between and within organisations. The implications of these structural problems should not be underestimated. For example, most major airlines operate their own in-house incident reporting schemes to cover both human and technical failures. Airframe manufacturers are then faced with the almost impossible task of amalgamating these dozens of different data sources before they can identify common failure modes. This has reached the stage where one manufacturer cannot tell from the compiled reports whether component failure was due to "erroneous" actions by maintenance personnel or to design problems with the component itself (Lainoff, 1999).
Partly as a result of the problems mentioned above, there have been a number of recent national and international initiatives to expand the scope of local incident reporting systems. Much of this work has taken the FAA’s Aviation Safety Reporting System (ASRS) as its model. This scheme was established in 1975 to collect, analyse, and respond to voluntarily submitted aviation safety incident reports in order to lessen the likelihood of aviation accidents. In particular, it has been used to "strengthen the foundation of aviation human factors safety research. This is particularly important since it is generally conceded that over two-thirds of all aviation accidents and incidents have their roots in human performance errors" (ASRS, 2000). Irrespective of whether these claims about the causes of aviation incidents are true, it is certainly the case that the perceived success of the ASRS has motivated the development of many more national and international initiatives.
3. An Overview of the ASRS
This section provides a brief overview of the ASRS system because it illustrates the problems of scale that are created by national reporting systems for human "error" and systems "failure". Approximately 650 reports are submitted per week with more than 30,000 reports being received each year. The current cumulative total is approaching half a million submissions
The ASRS is confidential but not anonymous. Each report is assessed to determine whether criminal prosecutions might arise from the incident. If this is not the case, then the report is checked to ensure that it does not reveal the reporter’s identity and it is categorised according to a number of different criteria. This is best illustrated by the sample report shown in Figure 1. This describes an Air Traffic Control incident in which the controller reports a collision between two aircraft that he directed to runway 19. Free text descriptions of the incident, the NARRATIVE, are supported by more strongly typed information about the systems that were involved, FACILITY IDENTIFIER, and about the nature of the incident, ANOMALY DESCRIPTIONS. It also provides information about the people or systems that identified the problem, ANOMALY DETECTOR, and mitigated its effects, ANOMALY RESOLUTION.
ACCESSION NUMBER : 425641
DATE OF OCCURRENCE : 9901
REPORTED BY : CTLR; ; ;
PERSONS FUNCTIONS : TWR,GC.FDMAN.CD; FLC,PLT; FLC,PLT;
FLIGHT CONDITIONS : VMC
REFERENCE FACILITY ID : TEB
FACILITY STATE : NJ
FACILITY TYPE : TWR; ARPT;
FACILITY IDENTIFIER : TEB; TEB;
AIRCRAFT TYPE : SMA; SMT;
ANOMALY DESCRIPTIONS : CONFLICT/GROUND CRITICAL;
ANOMALY DETECTOR : COCKPIT/FLC;
ANOMALY RESOLUTION : NOT RESOLVED/UNABLE;
ANOMALY CONSEQUENCES : NONE;
NARRATIVE : ON OR ABOUT XA50Z CESSNA ACFT X REQUESTED TAXI AND BEACON CODE FOR VFR FLT TO BED. WHILE I WAS TYPING INFO IN THE ARTS KEY PACK, ACFT Y CALLED FOR AN IFR CLRNC TO IAG. AFTER GETTING THE BEACON CODE FOR ACFT X, I READ IT TO HIM AND GAVE HIM TAXI FROM FBO-X TO RWY 19 AND HE ACKNOWLEDGED. I THEN READ ACFT Y HIS CLRNC TO IAG AND TOLD HIM TO ADVISE WHEN HE WAS READY TO TAXI. HE SAID HE WAS READY AND I ASKED IF HE COULD ACCEPT THE RWY 19 DALTON DEP, TO WHICH HE ANSWERED IN THE AFFIRMATIVE. I AMENDED HIS CLRNC TO THE RWY 19 DALTON DEP AND INSTRUCTED HIM TO TAXI TO RWY 19. AT XB55Z ACFT X RPTED A COLLISION WITH ACFT Y ON TXWY P. ACFT Y APPARENTLY WAS UNAWARE OF THE INCIDENT.
SYNOPSIS :ATCT CTLR AT TEB CLRS A C172 AND A C402 TO RWY 19 AND WHILE
TAXIING, THE C172 PLT RPTS COLLIDING WITH THE C402.
REFERENCE FACILITY ID : TEB
FACILITY STATE : NJ
DISTANCE &
BEARING FROM REF. : 0
AGL ALTITUDE : 0,0
Figure 1: Excerpt from the ASRS Air Traffic Control Collection (Aug. 1999)
The analysis that is performed to identify categories such ANOMALY RESOLUTION and ANOMALY DETECTOR has two purposes. Firstly, it supports statistical analysis. NASA and the FAA can assess the relative importance of key personnel and information systems both in detecting and resolving incidents. This analysis also supports the subsequent retrieval of incident reports. Individuals and organisations can issue queries against the ASRS data to retrieve all incidents with common detection or resolution factors. This occurs in two different ways. Firstly it is possible to acquire the ASRS data by purchasing CD ROMS that each contain 50,000 reports. Secondly, it is possible to request searches which can be performed by NASA on behalf of individuals and organisations. Approximately, 4,000 such requests have been made since the system was developed. It is not possible to perform on-line searches of the existing data.
Previous paragraphs have provided a brief overview of the ASRS scheme because it is indicative of the problems of scale that will affect the national schemes that have been proposed in the healthcare and rail industries. There is an important caveat to make, however. Given the relative frequency of airline departures to clinical procedures one might anticipate exponentially greater problems as these schemes are extended into other domains. Of course, this depends upon the reporting behaviour of operators in those domains and, to a lesser extent, upon the relative frequency of incidents in those domains. However, it seems safe to conclude that we can expect future incident reporting systems to face considerable problems of scale as they attempt to identify common themes and trends in the data that they receive.
4. Information Retrieval Techniques
All large-scale incident reporting systems, including the ASRS, currently rely upon computing technology that is over twenty years old. Relational database techniques have the advantages of being both well established and well understood. However, they also have many disadvantages compared to more recent technologies. For instance, they typically require a data model that must be explicitly designed prior to the system being implemented. This makes any resulting application very difficult to maintain in response to technological innovation or changing patterns of incidents within an industry. As a result, the ASRS and similar schemes tend to rely upon generic data models that do not exploit the full structuring powers of relational databases. This point is illustrated by Figure 1. Fields such as ANOMALY RESOLUTION and ANOMALY DETECTOR are defined for all incidents. Users can issue explicit queries to retrieve information about all incidents that were detected or resolved by agents such as COCKPIT/FLC. However, these techniques offer little or no support if users want to identify more detailed contextual information about the circumstances in which the incident occurred. In order to do this, additional support must be provided to search through the natural language descriptions in the synopsis or the narrative. The relational database techniques currently being used provide little or no support for doing this. It is, therefore, impossible to search these natural language fields to identify instances of "high workload" except through simplistic syntactic pattern matching. Ideally, it should also be possible to search for synonyms, metonyms and other phrases that have a more semantic relationship to the concepts that are being retrieved from large-scale incident reporting systems. This is particularly important where the individuals who are submitting the reports have no prior training in concepts such as workload or situation awareness. It is also critical when incident reports are being collated across regional and national boundaries or from different disciplines within the same business sector. Such diverse sources of incident reports are unlikely to share the same terminology even for behavioural descriptions of human error. In consequence, simple syntactic searching for terms such as "situation awareness" will provide little or no support for identifying common factors in their submissions.
The field of information retrieval has developed a range of techniques for performing searches that make use of semantic information about the relationships between the terms/phrases that appear in a document and the terms/phrases that appear in the users’ query. These techniques enable analysts to ensure that queries that contain terms such as "high workload" will also match incident reports that relate to concurrent operation, workplace stress and synchronisation. Brevity prevents a complete introduction to all of these techniques. However, the following paragraphs introduce some of the main features of the Inquery system (Turtle and Croft, 1991) that we have applied to support information retrieval within the ASRS incident reports.
Information retrieval techniques, typically, extract a number of indices from the documents that are being stored and retrieved. This process includes stemming; the morphological origin of a word is stored as an index so that any query about "misunderstanding" will also match with documents containing "misunderstood", "mistake" and "mistaken". "Plan" will match with "planned" and "planning". This initial stage can also include concept recognition where analysts identify critical semantic concepts that are to be explicitly tagged in the document set. In the ASRS incident reports this can include information about the stage of flight during which an incident occurred. It can also include, for example, references to the roles of the individuals mentioned in a report. The tagging stage can be performed automatically as new documents are entered, however, the initial concept recognition requires expert support.
This preliminary analysis also includes more complex processes, such as the generation of dictionaries that support query expansion. This identifies nouns that are used in similar contexts within different documents. For example, "Clearance" and "Flight level" occur in similar contexts but are not synonyms. As a result, they may not be grouped within standard thesauri but could usefully be employed to add more semantic information to a user’s query about an altitude bust. Our application of the Inquery tool generates probabilistic information based on the relative frequencies of these collocations. A key point here is that these weightings are entirely derived from the use of language within the collection and so reflect the domain specific features of that collection. As the use of language changes within the reports then these weightings and associations will be automatically updated.
The use of information retrieval techniques enables Inquery to form a network of terms and concepts that are considered to be relevant to a query. The retrieval system can then rank documents according to whether or not it believes that those documents are relevant to the query. Calculus can be used to combine the belief values that are associated with one or more concepts in the same document:
Bel_not(Q) = 1 – p_1 (1)
Bel_or(Q) = 1-(1-p_1) x … (1-p_n) (2)
Bel_and(Q) = p_1 x p_2 x … p_n (3)
Etc …
However, such automatic calculations have a number of important limitations. For instance, the weighting associated with a term can also be determined by its relative frequency within the collection of incident reports. If a term such as "situation awareness" occurs in a query but is only used infrequently in the collection then those documents that do contain the term are assigned a relatively high value. This process of assigning weightings can be taken one stage further by supporting relevance feedback. In this process, the user is asked to indicate which of the documents that the system proposed were actually relevant to their query. If a term occurred frequently in the relevant documents but infrequently in the corpus as a whole then that term shows a high degree of predictive reliability for that query.
The previous paragraphs provided a brief overview of how information retrieval techniques can be extended to support national and international incident reporting schemes. These techniques might appear to be irrelevant to those who are more interested in human error modelling. However, their application has profound consequences for practitioners. There has, for example, been considerable interest in mode confusion errors in recent years (Leveson et al 1997, Javaux 1999). It is at present impossible to judge the importance of this problem within the ASRS database because there are no facilities for translating between the pilot’s language and the higher level concepts that are used to characterise this form of human error. We have no idea how many of the 500,000 reports actually describe instances of this problem during flight. However, the semantic modelling techniques of systems such as Inquery make it possible to perform this type of search providing that human factors experts can guide the system by identifying the language that pilots might use when describing these incidents. This can be done not simply by weighting key terms, it can also be done using the relevance feedback techniques, mentioned above, to identify documents that are similar to those instances which are already known about. In other words, the application of innovative information retrieval techniques is crucially dependent upon the active participation of human factors experts in guiding both the automatic indexing of incident reports and of interpreting the queries that users make to the existing ASRS system. There has been no previous work in this area. As a result, we are compiling an increasing body of data that we cannot effectively analyse to identify common causes of human error or system failure.
5. Case Based Reasoning
Information retrieval techniques, such as those described above, have a number of disadvantages for incident reporting schemes. For example, users often face considerable problems when attempting to formulate either natural language or Boolean queries. The importance of this should not be underestimated. The performance of a user’s query is traditionally defined in terms of its precision and recall. A low precision query will result in many unwanted hits. A low recall query will result in many potentially relevant incidents not being returned. It is possible for a query to result in high recall but poor precision. In this case, all relevant incidents can be returned but so will many other irrelevant documents. Unfortunately, most users cannot easily tune their queries in either retrieval engines or in relational databases to improve both the precision and recall of their searches. As a result, it is entirely possible for users to issue queries that fail to find similar incidents. Conversely, other systems guarantee that only relevant documents will be retrieved but they also fail to return some of those documents (Johnson, 2000). They achieve good precision but poor recall.
Conversational case based reasoning tools avoid the problem of query formation by guiding users through what is known as a "case base". For instance, the US Naval Research Laboratory’s Conversational Decision Aids Environment (NaCoDAE) system was developed to support fault finding in complex systems. This application presents its users with a number of questions that must be answered in order to obtain information about previous failures. These questions partition the cases that the system knows about. For instance, if a user inputs the fact that they are facing a power failure then this will direct the system to assign greater relevance to those situations in which power was also unavailable. As a result, the system tailors the questions that are presented to the user to reflect those that can most effectively be used to discriminate between situations in which the power has failed. The performance of the system is determined by how many questions the user must answer before they are confident in their diagnosis. (Aha, Breslow and Munoz-Avila, 2000).
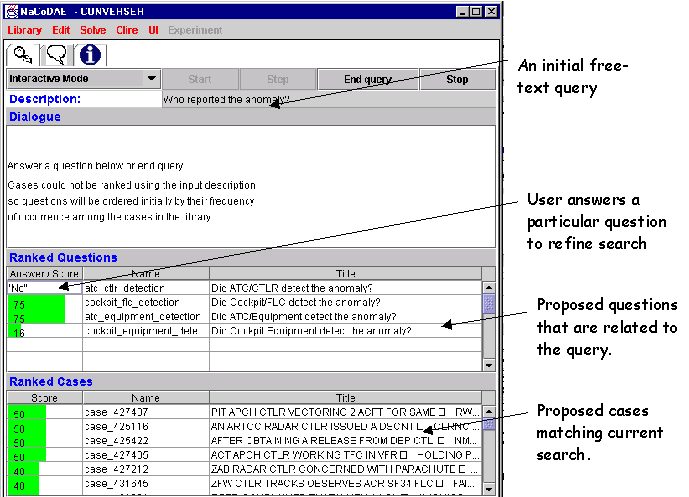
We have extended the application of the US Navy’s system from the domain of fault finding to support the indexing and retrieval of incident reports. Users can answer questions about an incident to retrieve other incidents that have similar causal factors, emerging behaviours or ultimate consequences. Figure 2 illustrates this application of the NaCoDAE tool. After loading the relevant case library, the user types in a free-text query. This is then matched against the cases in the library. Each case is composed of a problem description, some associated questions and if appropriate a description of remedial actions. The system then provides the user with two lists. The first provides questions that the system believes are related to the user’s original question. This helps to reduce the query formation problems that have been noted for other forms of search engine. The second list provides information about those cases that the system currently believes to match the situation that the user is confronted with.
Figure 2: US Navy’s NaCoDAE Tool
The previous paragraph indicates the critical nature of the questions that are encoded within the NaCoDAE system. Our study began by deriving these questions directly from the fields that are encoded in the ASRS. Users navigate the case base by answering questions about how the incident was resolved, what the consequences of the anomaly were, who identified the anomaly etc. If the user selected Cockpit/FLC as an answer to the question "Who detected the incident?" then all cases in which the flight crew did not detect the incident would be automatically moved down the list of potential matches.
It is important to emphasise that each incident report only contains answers to some of these questions. For instance, the person submitting the form may not know how it was resolved. This is useful for a case-based reasoning system because the absence of an answer to a question actually helps to distinguish between incidents; those for which an answer is provided are similar irrespective of that answer. The question-refinement techniques of NaCoDAE’s case-based reasoning system provide further benefits. Once a set of similar cases have been identified, it can look for questions that can be used to discriminate between those cases. For example, if some highly ranked cases were resolved by the Aircrew and others were resolved by Air Traffic Controllers then the system will automatically prompt the user to specify which of these groups they are interested in. This iterative selection of cases and prompting for answers from the user avoids the undirected and often fruitless query formation that is a common feature of other approaches.
There are two key points in this paper. The first is that additional tool support must be recruited if we are to make effective use of the large-scale incident reporting schemes that are being proposed for many different industries. The second is that our ability to use technologies, such as information retrieval engines and case based reasoning tools, is dependant upon our ability to exploit the insights provided by human error analysis. In terms of information retrieval engines, we have seen how mappings must be defined between the terms and concepts that operators use to describe instances of particular error forms, such as the mode confusion problems that have been identified for flight management systems (Javaux, 1999). For case based reasoning systems, it is important to use techniques from human error analysis to define the questions that are used to partition and search the case base. In particular, we have extended our initial case base that was constructed around the simple ASRS categories in Figure 1 to exploit the Eindhoven Classification scheme proposed by van der Schaaf (1996) and developed by van Vuuren (1998). This approach extends Rasmussen’s SKR taxonomy with the managerial and organisational factors that are the focus of Reason’s (1998) more recent work. Figure 3 shows how the elements of the incident taxonomy appear as leaf nodes in a graph. Analysts must determine whether organisational failure, technical factors, human behaviour or patient related factors caused the incident. If any of these causal factors were present then they must look along the graph to identify the more detailed causes. For example, analysts must determine whether an organisational failure stemmed from outside the unit. In the context of the Accident and Emergency department, this would arise when patients could not be transferred because of a shortage of beds in another department. Alternatively, organisational failure might stem from problems in the transfer of knowledge within the unit. At each stage, if a causal factor were identified then an appropriate label would be allocated to the incident. The O-EX label would be assigned if an incident were caused by a failure from outside the reporting organisation. If the incident stemmed from a failure of knowledge transfer within an organisation then the OK label would be used.
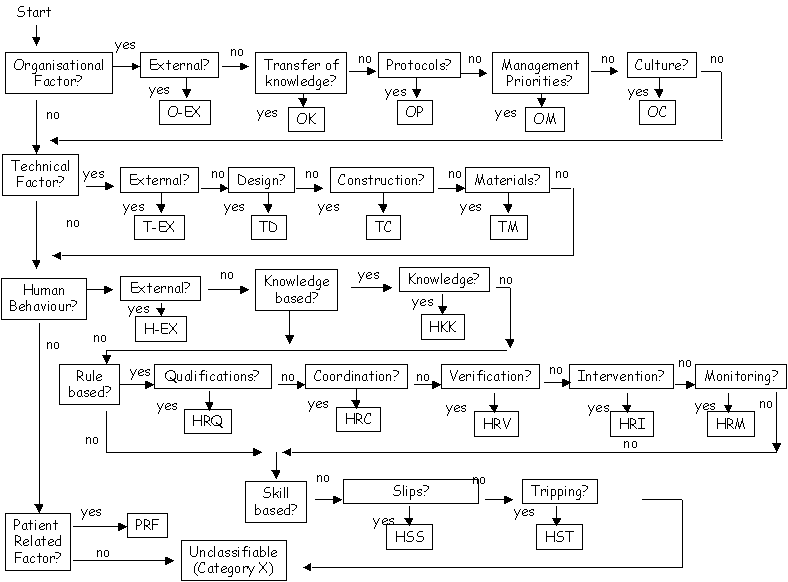
Figure 3: The Eindhoven Classification Method for Incident Analysis (van Wuren, 1998)
The results of this classification process have previously been used to support statistical analyses. For instance, a recent sample of 19 incident descriptions in a UK Accident and Emergency department yielded 93 root causes at an average of 4.9 per incident. 45% of these related to organisational causes whilst 41% related to (direct) human causes. Rather than use the Eindhoven model in this way, we have used it to guide the search process amongst the cases of human error that are described in the ASRS incident reports. For example, one altitude deviation in the ASRS data was caused by a co-ordination failure between the flight crew and the Air Traffic Controller. This was categorised by the HRC node shown in Figure 3. The same incident was also caused by a lack of adequate monitoring. It was, therefore, also assigned an HRM classification in the Eindhoven model. We then encoded this analysis as positive responses to the questions "was there an HRM problem?" and "was there an HRC problem?" As well as questions about the facts known for each incident, there are also questions about the causal analysis of those incidents. Not only does the system support direct queries of the form "who reported the incident" but it also supports searches that look for complex combinations of causes such as "what incidents were not reported by aircraft equipment but were caused by a lack of flight crew co-ordination". Such queries cannot easily be satisfied using conventional databases and information retrieval engines.
6. Conclusions
It is important to emphasise that we are not simply advocating the technologies that have been presented in this paper. Further work must be conducted to validate the potential offered by information retrieval engines, such as Inquery, and case tools, such as NaCoDAE. Nor are we arguing that the human error analysis tools that we have exploited are necessarily the best that might be recruited. In contrast, the key point is to show how we must integrate human error analysis techniques and information retrieval technology if we are to successfully manage and search large-scale incident reporting schemes. If this integration cannot be achieved then there is a danger that we will be submerged by a rising number of reports about human error. The plethora of systems being proposed for the UK National Health Service and European railway networks may result in a diverse number of ad hoc approaches being adopted. However, we have an opportunity to influence these initiatives to ensure that previous work in human error modelling guides the analysis of these collections. We must, therefore, scale-up error analysis techniques that can be applied by trained experts to small numbers of complex incidents so that they can also be applied to the mass of data that will be gathered by national and international incident reporting systems.
ACKNOWLEDGEMENTS
Thanks are due to the members of the Glasgow Interactive Systems Group and the Glasgow Accident Analysis Group. This work is supported, in part, by a grant from the UK Engineering and Physical Sciences Research Council.
REFERENCES
D. Aha, L.A. Breslow and H. Munoz-Avila, Conversational Case-Based Reasoning. Journal of Artificial Intelligence (2000, to appear).
Aviation Safety Reporting System, Overview - January 2000. Available from www-afo.arc.nasa.gov/ASRS/.
D. Busse and C.W. Johnson, Human Error in an Intensive Care Unit: A Cognitive Analysis of Critical Incidents. In J. Dixon (editor) 17th International Systems Safety Conference, Systems Safety Society, Unionville, Virginia, USA, 138-147, 1999.
A. Hale, B. Wilpert and M. Freitag, After the Event: From Accident to Organisational Learning. Pergammon, New York, 1997.
D. Javaux, The Prediction of Pilot Mode Interaction Difficulties: Spreading Activation Networks as an Explanation of Frequential and Infrequential Simplification. 10th International Symposium on Aviation Psychology, Columbus Ohio, 1999.
C.W. Johnson, Why Human Error Analysis Fails to Support Systems Development, Interacting with Computers, 11(5):517-524, 1999.
C.W. Johnson, Supporting the Retrieval of Reports about Human Error. To appear in Foresight and Precaution: ESREL/SRA’2000, Edinburgh, UK, May 2000.
S. Lainoff, Finding Human Error Evidence in Ordinary Airline Event Data. In M. Koch and J. Dixon (eds.) 17th International Systems Safety Conference, International Systems Safety Society, Orlando, Florida, 1999.
N.G. Leveson, L.D. Pinnel, S.D. Sandys, S. Koga, J.D.Reese, Analysing Software Specifications for Mode Confusion Potential. In C.W. Johnson (ed.) 1st Workshop on Human Error and System Development, Glasgow, Scotland 1997.
J. Reason, Managing the Risks of Organisational Accidents, Ashgate, Aldershot, 1998.
H.R. Turtle and W.B. Croft, Evaluation of an inference network-based retrieval model. ACM Transactions on Information Systems, 9(3):187-222, 1991.
T. van der Schaaf, PRISMA: A Risk Management Tool Based on Incident Analysis. International Workshop on Process Safety Management and Inherently Safer Processes, October 8-11, Orlando, Florida, 242-251, 1996.
W. van Vuuren, Organisational Failure: An Exploratory Study in the Steel Industry and the Medical Domain, PhD thesis, Technical University of Eindhoiven, Netherlands, 1998.