
Using Case-Based Reasoning to Support the Indexing and Retrieval of Incident Reports
Chris Johnson,
Department of Computing Science, University of Glasgow, Glasgow, G12 8QQ,
Tel: +44 141 330 6053, Fax: +44 141 330 4913
johnson@dcs.gla.ac.uk, http://www.dcs.gla.ac.uk/~johnson
Incident reporting systems can be used to detect problems before they result in an accident. They can also be used to strengthen the defences that lead to the detection and resolution of potential problems. There are also significant limitations. For instance, it is difficult to support long-term participation from all elements of a workforce. In spite of these difficulties, incident reporting schemes are increasingly being introduced into many industries. This growth is creating new challenges. In particular, it can be difficult to spot emerging trends and common features amongst the thousands of reports that are submitted to many international schemes. Traditional databases offer little support here because query formation often defeats even relatively skilled analysts. Similarly, free-text search engines have technical limitations that may it difficult to identify incidents in which certain causes were NOT a factor. As a result many of these systems yield results that have poor precision and low recall values. This paper, therefore, argues that alternative techniques must be developed to support the indexing and retrieval of similar cases from within the growing body of evidence in large-scale incident reporting schemes. In particular, we show how case-based reasoning techniques can be extended from the domain of decision support to help analysts retrieve information about previous incidents. The US Navy’s Conversational Decision Aids Environment (NaCoDAE) is used to illustrate this argument. In particular, we have applied it to two datasets from the US Aviation Safety Reporting System (ASRS). This initial work has exploited two different classification schemes. The first was based on part of the FAA’s ASRS reporting process. The second was based on the more general Eindhoven classification method.
Keywords: Case-based Reasoning; Accident Reporting; Incident Reporting.
Incident reports provide an important defence against future failures in many safety-critical industries. They provide engineers, designers, managers and operators with important guidance about potential problems in existing and proposed systems. The relative frequency of incidents, as opposed to the relative infrequency of accidents, helps to ensure that there is a continuing focus on safety issues (Reason, 1998). Incident reports are also amenable to statistical analysis in a way that accident reports are not (van Wuuren, 1998). Of course, there are important limitations with these systems. For example, they often suffer from reporting bias. It can be difficult to ensure that all sections of a workforce continue to participate in the reporting of incidents. There are also problems associated with maintaining trust in the anonymity or confidentiality of such systems. In spite of these difficulties, more and more industries are relying upon the insights provided by incident reporting schemes (van der Schaaf, 1996).
2. The Benefits of Incident Reporting
Incident reporting systems provide a number of benefits for the design and operation of safety-critical applications. The following list summarises the arguments that have been made in favour of these systems:
Many incident reporting forms identify the barriers that prevent adverse situations from developing into a major accident. These insights are very important. They help analysts to identify where additional support is required in order to guarantee the future benefits of those safeguards.
It can be argued that many accidents stem from atypical situations. They, therefore, provide relatively little information about the nature of future failures. In contrast, the higher frequency of incidents provides greater insights into the relative proportions of particular classes of human "error" and systems "failure".
Incident reports provide a means of monitoring potential problems as they recur during the lifetime of an application. The documentation of these problems increases the likelihood that recurrent failures will be noticed and acted upon (Johnson, 1999).
Incident reporting schemes provide a means of encouraging staff participation in safety improvement. In a well-run system, they can see that their concerns are treated seriously and are acted upon by the organisation.
Incident reporting systems provide the raw data for comparisons both within and between industries. If common causes of incidents can be observed then, it is argued, common solutions can be found. However, in practice, the lack of national and international standards for incident reporting prevents designers and managers from gaining a clear view of the relative priorities of such safety improvements. This paper deals with the consequences of promoting these international reporting schemes.
These is an argument that the relatively low costs of managing an incident reporting scheme should be offset against the costs of failing to prevent an accident. This is a persuasive argument. However, there is also a concern that punitive damages may be levied if an organisation fails to act upon the causes of an incident that subsequently contribute towards an accident.
The final argument in favour of incident reporting is that these schemes are increasingly being required by regulatory agencies as evidence of an appropriate safety culture.
A number of problems must be addressed before incident reporting systems can deliver the benefits listed above. For instance, there is a legitimate concern that information about incidents will be used to discipline or blame staff rather than guide to other forms of safety improvement. It can also be difficult to ensure uniform participation rates amongst many different levels of staff. For example, many clinical systems have found it difficult to guarantee participation from both nursing and medical staff (van Wuren, 1998). It can also be difficult to develop appropriate forms that help people report incidents to a sufficient level of detail and that aren’t perceived to be a "waste of time". Other problems relate less to the issues of data acquisition and more to the problems of data analysis. These issues are at the heart of this paper and so the next section describes them in greater detail.
3. Problems of Scale
In the past, many reporting systems operated at a local level. For instance, several UK hospitals have pre-empted recent moves towards national incident report systems by setting up their own schemes (Busse and Johnson, 1999). There has, however, been an increasing emphasis upon the development of larger systems. Some of this has stemmed from the development of local initiatives. Sven Staender and his colleagues at the University of Basel have attempted to establish a national scheme for incident reporting in Anaesthesia (Staender, Kaufman and Scheidegger, 1999). The increasing coverage of incident reporting systems has also been driven by international agreements.
The initiatives mentioned in the previous paragraph have all built upon the perceived success of the FAA’s Aviation Safety Reporting System (see http://www-afo.arc.nasa.gov/ASRS). This was established in 1976 to provide a national system for aviation incident reporting in the United States. It now receives an average of more than 2,600 reports per month. The cumulative total is now approaching half a million reports from pilots, air traffic controllers, flight attendants, mechanics etc.
It is a non-trivial task to analyse the mass of data that can be gathered by national and international reporting schemes. In particular, it can be difficult to identify common causes amongst the thousands of reports that are received each year. Incident taxonomies have been proposed as one solution to this problem. These provide a list of causal factors that contribute to many different incidents. Analysts then use these taxonomies to select a number of different labels or keywords that represent each adverse event that is reported to the scheme. The total frequency for each of these causal factors can be calculated over the entire collection to identify possible priorities for future safety improvements. However, this approach depends upon a high degree of consistency between the different analysts who assign the keywords to each incident. If they do not follow an agreed set of procedures during this assignment phase then there can be little confidence about the true frequency of incidents being caused by each of the factors in the taxonomy. Incident classification schemes provide a means of improving such consistency.
Figure 1 illustrates a domain-specific classification scheme (van Wuren, 1998). The elements of the incident taxonomy appear as leaf nodes in the graph. This particular scheme was developed to cope with the diverse range of incidents that were reported within a UK Accident and Emergency Department. A number of analytical stages precede the use of this model. However, the key point is that analysts must determine whether organisational failure, technical factors, human behaviour or patient related factors caused the incident. If any of these causal factors were present then they must look along the flow chart to identify the more detailed causes. For example, analysts must determine whether an organisational failure stemmed from outside the unit. In the context of the Accident and Emergency department, this would arise when patients could not be transferred because of a shortage of beds in another department. Alternatively, organisational failure might stem from problems in the transfer of knowledge within the unit. At each stage, if a causal factor were identified then an appropriate label would be allocated to the incident. The O-EX label would be assigned if an incident were caused by a failure from outside the reporting organisation. If the incident stemmed from a failure of knowledge transfer within an organisation then the OK label would be used.
Figure 1: The Eindhoven Classification Method for Incident Analysis (van Wuren, 1998)
The results of this classification process can then be used to drive statistical analysis. For instance, a recent sample of 19 incident descriptions in a UK Accident and Emergency department yielded 93 root causes at an average of 4.9 per incident. 45% of these related to organisational causes whilst 41% related to (direct) human causes. Figure 2 illustrates the sorts of graphs that can be produced using the classification system illustrated in Figure 1.
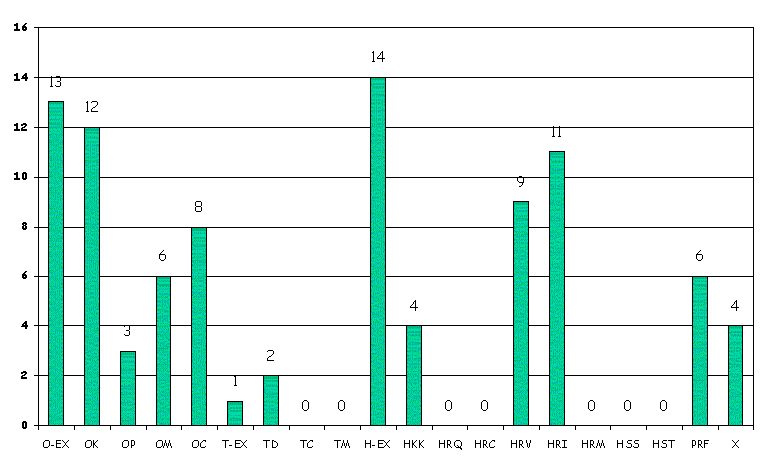
Figure 2: Results of Eindhoven Approach for a UK A&E Department (van Wuren, 1998).
Unfortunately, it is a non-trivial task to develop classification schemes such as that shown in Figure 1. There are no widely accepted criteria that can be applied to classify common causal factors in incident reporting schemes (Busse and Johnson, 1999). Further problems are listed below:
1 How do we Avoid Confirmation Bias?
There is a risk that causal taxonomies will reflect existing safety priorities and will mask other causal factors. The last five years have seen a growing focus on "situation awareness" within the human factors community. Prior to that there was a similar concern about "high workload". This has resulted in the introduction of these terms into many causal taxonomies. Partly in consequence, there is a growing body of evidence that points to these problems as major causes of incidents in the aviation, maritime and clinical areas. There is, therefore, a concern that taxonomies will devolve into a list of "hot topics" rather than a coherent catalogue of causal factors.
2 How to Identify an Appropriate Level of Abstraction?
On the one hand, it is important to identify a sufficient range of issues so that all factors can be classified. On the other hand, it is important not to define too many causal factors because it then becomes extremely unlikely that two analysts will agree on the precise labelling associated with any incident. A high level of abstraction reduced the time required to perform an analysis and increases the level of consistency that is likely within a reporting scheme. A low level of abstraction helps to distinguish more fine-grained causes and can increase confidence in the detailed recommendations from a scheme.
3 What to do when Incidents Change?
If a low-level taxonomy is chosen then it is extremely likely that it will be revised over time. This is not simply due to the inherent problem of enumerating all causal factors. It is also due to technological, managerial and operational change. For example, the US ASRS has been used to track the impact of new technology, such as TCAS II, on aviation related incidents. This is less of an issue in high level taxonomies where general terms are more likely to act as catch-all’s for technological change.
4 How do we Decide what is Relevant?
The difficulties associated with the use of incident classification schemes are complicated by the fact that analysts must often reclassify previous incidents in the light of new data. Most typically this occurs in the aftermath of an accident. Such major failures increase the salience of particular causal factors. In extreme circumstances this can introduce new causal factors that may already have been recognised in the initial reports but which were not considered significant enough to be included in the taxonomy.
5. How do we Keep Track of Complex Causal Relationships?
Perhaps the greatest limitation of incident classification schemes is that they strip each causal factor from the context in which it arose. This makes it difficult to answer questions such as "what other causal factors were most likely to contribute to communication failures during an incident?"
The Eindhoven classification scheme, illustrated in Figures 1 and 2, does not suffer from many of the limitations mentioned above. It avoids confirmation bias by exploiting Rasmussen’s (1983) SKR model rather than listing critical issues, such as "high workload". It also supports a number of levels of abstraction; this was the second problem identified for incident analysis schemes. For example, there is a clear relationship between higher level classifications, such as human behavioural causes, and lower level issues, such as a failure in monitoring. The Eindhoven classification scheme can also be further refined to introduce additional levels of detail and abstraction. The third problem for analysis schemes, mentioned above, is one of revision. The focus in the previous diagram on generic issues and not on technology helps to make the approach resistant to the impact of new systems. However, as mentioned above, these more detailed technological issues might be introduced as additional leaf nodes within a revised hierarchy.
The previous paragraph has briefly argued that the Eindhoven approach avoids many of the limitations associated with incident classification schemes. There are, however, a number of remaining problems. In particular, automated support is required if this approach is to be applied to large datasets. Changes to such causal taxonomies currently force analysts to manually revise every record of every incident. The following section, therefore, introduces case-based reasoning as a technology that might be used to support the application of classification schemes in large-scale reporting systems.
4. Case-based Reasoning
The previous section has identified a number of limitations that frustrate attempts to maintain classification schemes for incident reports. These problems not only frustrate the manual analysis of incident reports; they also complicate attempts to provide the automated assistance that is essential for large-scale systems. For example, conventional databases use strictly defined data-models to structure the information that is recorded about an incident. As a result, it is difficult to change the data that is recorded about incidents as new causes are identified. Alternatively, free-text retrieval techniques and search engines can be used to search for common causal factors in incident databases. In previous work, we have followed this approach by running web-based, search engines over sections of the ASRS database. These approaches avoid the problems associated with strictly defined data-models and classification schemes. Users can enter natural language descriptions of each incident. Requests can be expressed as (pseudo) natural language queries.
There are, however, a number of problems with the use of conventional search engines for the indexing and retrieval of incident reports. In particular, this apprach depends on the limited precision and recall of many information retrieval tools. Precision is defined as the proportion of documents that the user considers being relevant within the total number of incidents that are retrieved. Recall is defined as the proportion of relevant documents that are retrieved against the total number of relevant documents within the entire collection. Hence an information retrieval system may have high recall and poor precision if it returns a large number of the relevant incidents in the entire collection but these incidents are hidden by a mass of irrelevant incidents that are also retrieved. Another system can have good precision and poor recall if it returns very relevant incidents but only a small proportion of those that pertain to the topic of interest. It is important to understand that precision and recall are not static qualities that relate simply to the design of the information retrieval engine. They can also be assessed for a query with respect to the users’ intention (Johnson and Dunlop, 1998). Many users have great difficulty in composing free-text queries that achieve a desired level of precision or recall. Most searches provide a small number of appropriate documents with many more irrelevant references. This poor level of precision is matched by unsatisfactory recall. It is rare that any single query will yield all of the possible references that might support a user’s task. These limitations are understandable given the dynamism and diversity of the web. They impose significant constraints for incident reporting systems. There are clear safety implications if a search engine fails to return information about similar incidents.
Case-based reasoning techniques relax some of the strict classification requirements that characterise more traditional databases. They do not avoid the concerns over precision and recall that affect other information retrieval tools. However, they often provide explicit support for users who must issue queries to identify similar classes of incidents within a reporting system. Ram provides an overview of case-based reasoning:
"Case-based reasoning programs deal with the issue of using past experiences or cases to understand, plan for, or learn from novel situations. This happens according to the following process: (a) use the problem description to get reminded of old cases; (b) retrieve the results of processing the old case and pass them to the problem-solver; (c) adapt the results from the old cases to the specifics of the new situation and (d) apply the adapted results to the new situation. In some case-based reasoning programs, there is a further step (e) in which the old and new solutions are generalised to increase the applicability of the solutions." (Ram, 1993).
Cases can be represented in a number of ways. For instance, feature vectors can be used to represent whether or not particular terms are relevant to a case. There are a number of well-understood revision algorithms that cope with the introduction both of new cases and of new features (Lenz, Bartsch-Sporl, Burckhard and Weiss, 1998). Alternatively, semantic networks can be used to model more meaningful features of the domain. This approach offers considerable benefits. It enables complex relationships to be induced through the analysis of cases as they are entered into the system. However, it also introduces considerable computational complexity. The net effect of both approaches is to enable engineers and analysts to find previous cases that have similarities to the incident in hand. They have been widely applied to support a number of decision-making tasks. For instance, the US Naval Research Laboratory has developed case-based reasoning tools that are intended to support complex faultfinding tasks (Aha, Breslow and Munoz-Avila, 1999). The designers of these systems provide a number of key questions that users must answer in order to obtain information about how to resolve particular failures. The answers to these questions effectively partition the cases that the system knows about. For instance, if a user inputs the fact that they are facing a power failure then this will direct the system to assign greater relevance to those situations in which power was also unavailable. The answers to these questions provide the problem descriptions that are alluded to in Ram’s overview. The performance of the system is determined by how many questions the user must answer before the user is confident in their diagnosis.
Conversational case-based reasoning systems, such as that described above, can learn in a number of ways. Firstly, new cases can be added to the system. This increases the set of possible solutions to each of the questions that partition the case-base. The person entering the case must explicitly indicate the position of that case within the case-base. Alternatively, new questions can be added to the case-based system. This introduces new partitions. As there are no predetermined rules about the sequences in which questions are asked, this enables users to explore the cases in the system with a great degree of flexibility. Conversely, the fact that the cases are grouped by the successive resolution of pre-defined questions helps to avoid the precision and recall questions that affect the users of free-text query systems. As we shall see, it is entirely possible to develop hybrid systems in which pre-defined and ad hoc retrieval techniques can be combined.
Case-based reasoning offers considerable potential as a means of indexing and retrieving accounts of previous failures. Users can answer questions about an incident to retrieve other incidents that have similar causal factors, emerging behaviours or ultimate consequences. Ram’s overview of case-based reasoning, cited above, also stresses that these similar cases will change over time. The introduction of new cases and questions will alter the links between related incidents. In other words, the case-base will reorganise itself to reflect changes during the operation of the system. The absence of such dynamic behaviour was criticised as an important limitation of existing approaches to incident classification. There are strong parallels between such faultfinding applications and the querying strategies that are employed with incident reporting systems. Rather than finding similar faults in an electrical system, analysts must find similar cases to the one being reported. Just as existing decision support tools help their users to identify solutions to a problem by retrieving the steps that were taken in similar cases, incident investigators can use the same techniques to determine what actions were taken in response to similar failures. The following section describes two ways in which we have applied the US Navy’s NaCoDAE case-based reasoning tool to a subset of the ASRS database. The intention is to determine whether the claimed benefits of case-based reasoning can be obtained using existing technology.
5 Application of Case-Based Reasoning to ASRS Air Traffic Management Incidents
This section describes how we have applied the US Navy Research Laboratories NaCoDAE (the Navy Conversational Decision Aids Environment) case-based reasoning system to store and retrieve incidents from two different subsets of data within the FAA’s Aviation Safety Reporting System.
5.1 A Brief Introduction to NaCoDAE
NaCoDAE was built by members of the Intelligent Decision Aids Group at the Navy Centre for Applied Research in Artificial Intelligence. It has been developed to help US Department of Defence personnel in producing decision aids. It exploits the conversational, case-based reasoning technology, described above. Users interact with the system by incrementally providing a problem description that NaCoDAE matches with the cases. In conventional applications, these cases consist of problem/solution pairs. NaCoDAE responds to this ongoing dialogue with two displays of ranked items. The first lists the questions whose answers, if given, help to refine the problem description. The second lists the most similar stored cases. The user has the option of answering more questions or selecting a case which matches their current situation.
Figure 3 illustrates NaCoDAE being used to diagnose a problem with a printer. After loading the relevant case library, the user types in a free-text query. This is then matched against the cases in this library. Recall that each case is composed of a problem description, some associated questions and, if appropriate, a description of remedial actions. The system then provides the user with two lists. The first provides a list of questions that the system believes are related to the user’s original question. This helps to reduce the query formation problems that have been noted for other forms of search engine. The second list provides information about those cases that the system currently believes to match the situation that the user is confronted with.
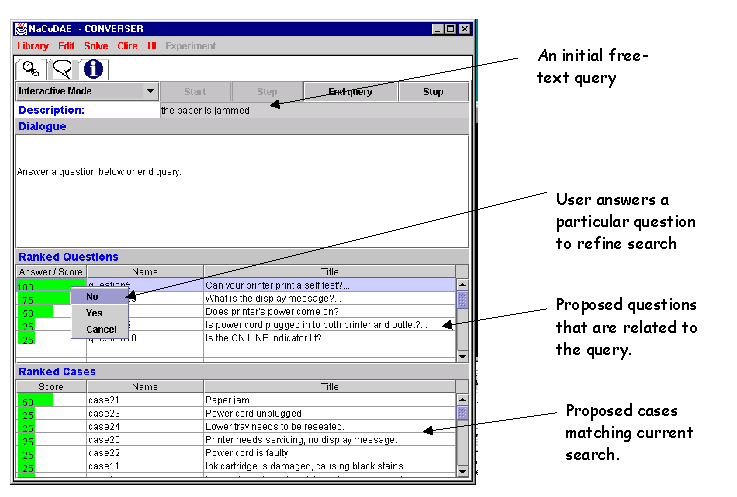
Figure 3: Overview of the US Navy’s NaCoDAE Case-Based Reasoning Tool
In Figure 3, the user has typed the query "paper is jammed". The system has responded with a list of questions headed by "Can your printer print a self-test". The user has selected the answer "No" – the intention here is to guide the user to increase the precision of the cases retrieved. As the user selects this question, the cases displayed below will be revised in the light of this additional information. This co-operative exchange of questions and answers will also help improve recall because the user can continually review the list of "relevant" cases being retrieved at each stage of the process. The user can select and display any of the cases that are shown in the second of these lists. The encoding for the printer example is illustrated in Figure 4. The format and presentation of this data can be tailored to support particular decision making tasks. This Figure simply shows the raw encoding as it is held within NaCoDAE.
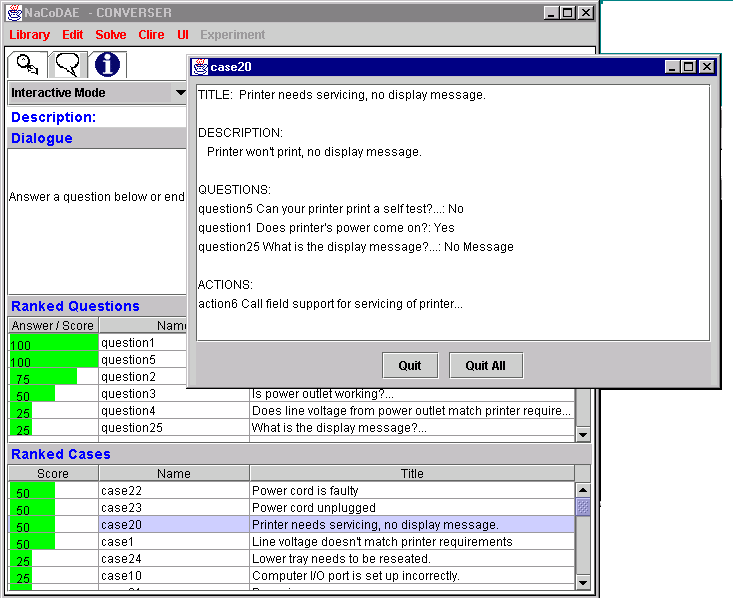
Figure 4: An Example NaCoDAE case
5.2 The ASRS Dataset
The NASA Ames Research Centre provides public access to the anonymised reports that are submitted to the ASRS system. These reports are categorised into a number of submission areas. For example, reports that address flight crew fatigue are separated from reports that deal with altitude deviations. Automated weather system reports are separated from reports by Cabin attendants. Typically, each set of reports contains the 50 most recent submissions within each of these categories. The data is stored in Rich Text Format (RTF) and can be exchange between a number of different text processing systems. Figure 5 contains one report from the collection of Checklist incidents.
ACCESSION NUMBER : 396693
DATE OF OCCURRENCE : 9803
REPORTED BY : FLC;
PERSONS FUNCTIONS : FLC,PLT;
FLIGHT CONDITIONS : VMC
REFERENCE FACILITY ID : MMH
FACILITY STATE : CA
FACILITY TYPE : ARPT;
FACILITY IDENTIFIER : MMH;
AIRCRAFT TYPE : SMA;
ANOMALY DESCRIPTIONS : OTHER; NON ADHERENCE LEGAL RQMT/PUBLISHED PROC; NON ADHERENCE LEGAL RQMT/FAR;
ANOMALY DETECTOR : COCKPIT/FLC; COCKPIT/EQUIPMENT;
ANOMALY RESOLUTION : NOT RESOLVED/DETECTED AFTER-THE-FACT;
ANOMALY CONSEQUENCES : ACFT DAMAGED;
NARRATIVE : I LANDED AN AIRPLANE WITH THE LNDG GEAR UP BECAUSE I FORGOT TO PUT THE GEAR HANDLE DOWN. I IMPROPERLY USED THE CHKLIST, MISSING THE LNDG GEAR PART. ALSO, THE LNDG GEAR HANDLE IS DIFFICULT TO SEE BECAUSE IT IS HIDDEN BY THE FLT YOKE. THAT MAKES THE AIRPLANE APPEAR TO BE A FIXED GEAR TYPE. I WILL USE A PROPER CHKLIST FOR EACH DIFFERENT TYPE OF AIRPLANE TO PREVENT FROM MISSING ITEMS ON THE CHKLIST. I SUGGEST ALL RETRACTABLE TYPE OF AIRPLANES SHOULD HAVE AT LEAST A VISUAL WARNING ON THE TOP PART OF THE PANEL IN CONJUNCTION WITH THE AUDIBLE WARNING.
MAKE-MODEL NAME : SKYLANE 182/RG TURBO SKYLANE/RG;
FAR PART NUMBER : 91;
SYNOPSIS : A C182 PLT LANDED GEAR UP. THE PLT ADMITS THE ERROR AND STATES THAT HE IMPROPERLY USED THE CHKLIST.
REFERENCE FACILITY ID : MMH
FACILITY STATE : CA
DISTANCE & BEARING FROM REF. : 0
AGL ALTITUDE : 0,0
Figure 5: Excerpt from the ASRS Checklist Reports Collection (August 1999)
We chose to focus on the ASRS data because it is publicly available and because it is widely regarded as one of the most successful, large-scale incident reporting systems. Within this dataset, we chose to focus on the reports submitted about Air Traffic Management incidents and on reports about incident involving Rotary Wing Aircraft. These different sets capture the variety of operations that can be reported within an incident analysis system: the rotary aircraft dataset reflects the diversity of tasks that helicopters are called on to perform. These sets also capture the strong common features that emerge from the repeated performance of similar tasks. It was felt that this was an attribute of ATM activities, although subsequent analysis and discussion revealed that this is only partly true. Figure 6 shows the summary lines for a portion of the ASRS Air Traffic Management reports that were entered into NaCoDAE.
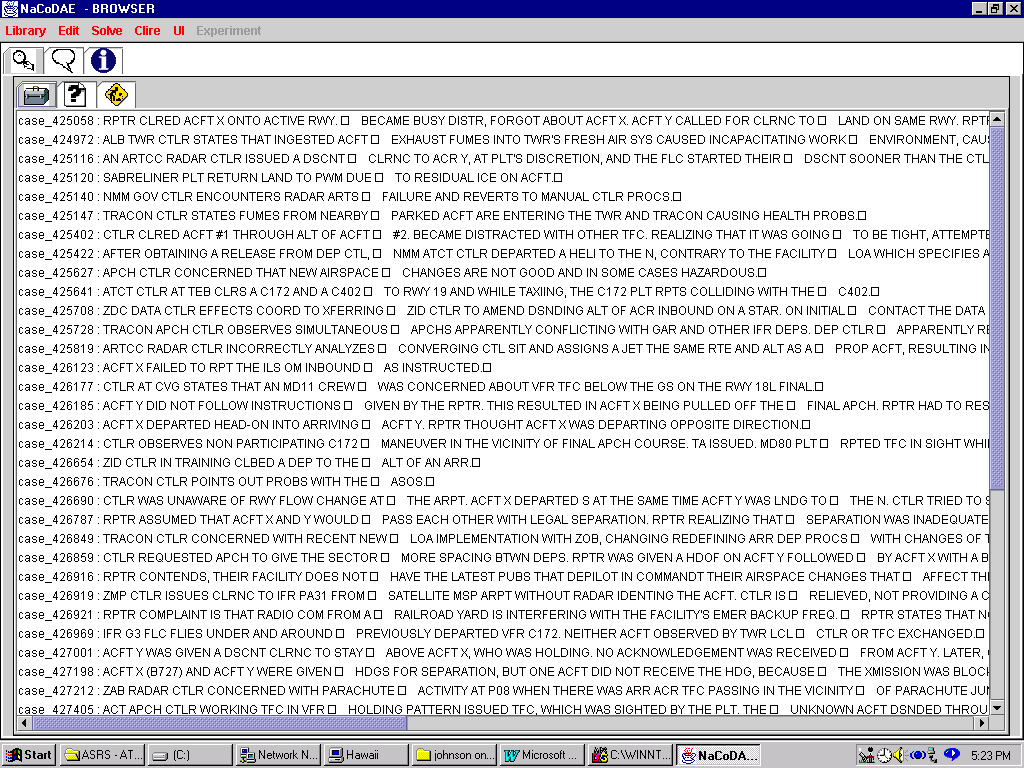
Figure 6: Summary of the ATM Incidents Stored in NaCoDAE
Previous sections have described how NaCoDAE represents each case in terms of a free-test description, a set of appropriate actions and the answers to questions that help to classify the case. The raw ASRS datasets readily provided descriptions for each incident in the form of the free-text reports that were associated with each record. However, more fundamental "design" issues were created by the questions and associated actions that are used in NaCoDAE.

Figure 7: Individual ATM Incident Description Stored in NaCoDAE
5.3 Using the ASRS Labels to Guide Search within a Case-based System
The questions that are associated with each case in NaCoDAE help to guide the system; similar cases are denoted by similar questions and, more strongly, by similar answers to those questions. As users’ successively select and answer questions, the system can use the highly ranked cases to identify further questions that might also be relevant to the search task. For instance, the user might indicate that they were interested in anomalies that involved altitude excursions. They would do this by selecting a positive answer to the question "did the anomaly involve an altitude excursion?" This might result in the retrieval of a number of cases that contained either positive or negative answers to the question "was the anomaly reported by the flight crew?" This question would then be presented to the user as a way of further refining their search using information that was common to the cases from their initial query.
The previous paragraph indicates the critical nature of the questions that are encoded within the NaCoDAE system. Our study began by deriving these questions directly from the information that is provided in the ASRS datasets. Figure 5 illustrates how each report includes answers to a number of questions in addition to the free-text descriptions. These answers provide information about how the anomaly was resolved, what the consequences of the anomaly were, who identified the anomaly etc. These questions and their associated answers can be directly encoded within NaCoDAE and can, therefore, help to distinguish one case from another. For example, incidents can be distinguished by different answers to the question about the eventual outcome of an anomaly.
It is important to emphasise that each incident report only contains answers to some of these questions. For instance, the person submitting the form may not know how it was resolved. This is useful for a case-based reasoning system because the absence of an answer to a question actually helps to distinguish between incidents; those for which an answer is provided are similar irrespective of that answer. Such "absent" values often cause problems for other retrieval systems where they can be confused with "don’t care" tokens. Therefore, for each case in the system we encoded both the free-text description and the answers to any additional questions that were provided on the ASRS submission.
Figure 8 illustrates an interactive session with the resulting implementation. In this case, the user has entered a free-text query about incidents that were identified by Air Traffic Controllers. After browsing cases that satisfy this constraint, they then requested information about incidents that were not detected by Air Traffic Controllers. As mentioned above, such negative queries are not well supported by many existing search engines. They cannot be performed using standard web-based system; there are considerable performance implications if the user asked for all web pages not containing the term "aircraft". In contrast, NaCoDAE only encodes negative answers where they are definitely known to be negative. It, therefore, responds with the list of incidents that were not detected by Controllers.
The explicit use of negation within NaCoDAE creates a number of potential problems. There may still be a large number of cases that were not detected by ATM controllers. Fortunately, the question-refinement techniques of NaCoDAE’s case-based reasoning system help to avoid these problems. As described earlier, the system looks for further relevant questions that are common to the highly ranked cases that have been retrieved in response to previous questions. In our example, the incidents that were explicitly not detected by Air Traffic Controllers also had answers indicated for three further questions. These are presented so that the user can refine their search: did the cockpit flight crew detect the anomaly? Did air traffic control equipment detect the anomaly? Did cockpit equipment detect the anomaly? As mentioned, this iterative selection of cases and prompting for answers from the user can help to direct the search task so that similar incidents can be identified. It also avoids the undirected and often fruitless query formation that is a common feature of other approaches.
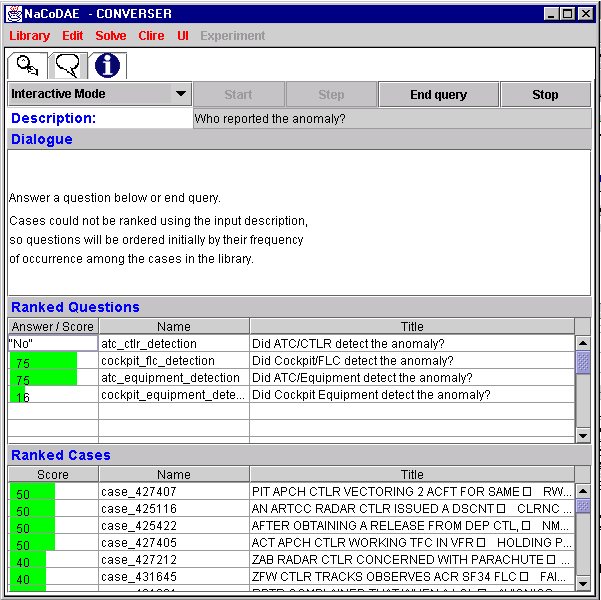
Figure 8: Using ASRS Questions to Guide Case-Based Retrieval
To summarise, the initial application of the US Navy’s NaCoDAE case-based system to the ASRS demonstrated two key benefits. Firstly, it provided an elegant solution to the problem of negation in queries. The significance of this should not be underestimated, as it is frequently important to identify similar incidents that differ in one or more particular (Busse and Johnson, 1999). Secondly, the use of both descriptions and questions in the encoding of incidents helped to direct the iterative task of refining queries during retrieval tasks. By restricting the questions to only those which the ASRS provides, we were confident that our encoding did not further distort the incident reports that were published by NASA and the FAA.
5.4 Using the Eindhoven Classification to Guide the Case-based System
Our initial use of the ASRS dataset restricted itself to the information that was included in the original reports. Section 3, however, argued that further insights can be gained through more detailed causal analyses. These insights also motivate the Eindhoven classification scheme. Further discussion with Neil Johnston of Aer Lingus, Mike O’Leary of British Airways and Floor Koorneef at the Technical University of Delft suggested that these causal analyses might also be used to guide the retrieval process within a case-based reasoning tool. We, therefore, decided to re-code the ASRS datasets that were used in the initial application of the NaCoDAE system.
The first stage of this new work was to perform a causal analysis of the incident reports. This followed the scheme proposed by van Wuren (1998) (see section 3). It produced a classification for each incident that consisted of a number of the causal factors identified in the Eindhoven classification. For example, one altitude deviation in the ASRS dataset was caused by a co-ordination failure between the flight crew and the Air Traffic Controller. This was categorised by the HRC node shown in Figure 1. The same incident was also caused by a lack of adequate monitoring. It was, therefore, also assigned an HRM classification in the Eindhoven model. We then encoded this analysis as positive responses to the questions "was there an HRM problem?" and "was there an HRC problem?"
As mentioned in previous sections, we did not have to provide answers about where or not each element of the Eindhoven classification was a causal factor for every incident. Answers were only provided when there was definite evidence for or against particular causal factors.
The resulting case-base was similar to that shown in Figure 8. Instead of questions about the facts known for each incident, there were also questions about the causal analysis of those incidents. Not only did the system support direct queries of the form "who reported the incident" but it also supported searches that looked for complex combinations of causes such as "what incidents were not reported by aircraft equipment but were caused by a lack of flight crew co-ordination". Such queries cannot easily be satisfied using conventional databases and information retrieval engines.
6. Further Work
This paper reports the results of applying case-based reasoning tools to large scale, incident-reporting systems. There are, however, many unanswered questions.
6.1 The Situation Assessment Problem
The central problem of case-based reasoning is how to generalise from the specifics of one particular case so that several previous incidents might be recognised as being similar. This is not as straightforward as it might appear. For instance, two incidents might share common causes but different outcomes. Alternatively, other incidents might have different causes but the same consequences. Any attempt to use case-based reasoning to support incident analysis must carefully consider what it means for two incidents to be classified as similar. In practice it is possible to identify at least five possible situations:
1. Exact match
This situation is relatively straightforward. Two incidents have identical causes and consequences. Such similarities should not be discounted as unlikely given the increasing scale of many reporting schemes. They are also particularly significant because they indicate a sustained weakness in the system.
2. Extension
One incident matches another case but has additional causes or consequences that were either missing in the other report or which are unique to the incident being examined.
3. Local consequence divergence
Two incidents share the same causes but at some point a new factor was introduced or described so that those consequent events diverged.
4. Local causal divergence
Two incidents have the same outcome but have different causes.
5. Global divergence
Two incidents have no common causes nor do they share common consequences.
Case-based reasoning exploits some of these distinctions. For instance, an exact matching offers considerable efficiency gains because two cases can effectively be treated as a single more general case during the partitioning processes, mentioned above. An extension can be used to generate new indices or labels, see below, that distinguish the additional causes or consequences that have been identified. Although we have focused on cause and consequence divergence, these are only instances of a more general problem. Where we have matches between aspects of a case, it may be important to report these divergences to the user. NaCoDAE supports this to a certain degree by exploiting differences in the questions and answers that are associated with the various cases. However, more work is needed to identify appropriate encodings so that the questions reflect the similarities and differences between cases that analysts actually consider being significant. The work, reported in this paper, avoids this problem by exploiting existing ASRS encodings and a classification scheme that has been validated by the Eindhoven group (van der Schaaf, 1996). More work is needed to determine whether these classifications are really appropriate for incident retrieval in the same way that they are appropriate for statistical and analytical purposes.
It is difficult, if not impossible, to derive a unique partition for any case-base such that for any given retrieval task each case is identified as either falling into one of the preceding categories. For instance, it is seldom possible to be certain that any two cases share exactly the same causal factors or indeed result in the same consequences. However, such distinctions are critical if we are to improve our understanding both of why different incidents occur and of why accidents are avoided. The former relates to local causal divergence whilst the latter stems from consequence divergence.
6.2 The Feedback Problem
A further issue that must be considered during the application of case-based reasoning is how to provide the system with feedback when the user disagrees with the matches that are proposed for particular incidents. This is complicated by the fact that labels may have been assigned as the result of inferential mechanisms. It is, therefore, important to provide the user with feedback about the reasons why the system chose previous accidents as being similar to the one under discussion. Some systems address this issue by simply showing the user a trace of all of the factors that match between the situation that they are describing and the one that has been retrieved. Under such circumstances, the user can then either revise their interaction with the system or alter the labels associated with the case that was erroneously retrieved. This latter option has clear implications for the coherence and consistency of the system if arbitrary users can alter label assignments.
There are a number of options that can be exploited if discrepancies arise between the users’ expectations and the systems’ responses. For instance, a list of exceptions might be created from the cases that were considered not to be relevant to the existing retrieval task. These represent the divergent cases mentioned in previous paragraphs. Ideally, the user should then be directed to provide additional labels that can be used to distinguish the erroneous situations from those that were correctly retrieved. Conversely, the additional labels might be associated with those cases that were correctly retrieved.
Previous paragraphs focussed on the precision of the case-based retrieval. Other problems stem from the efficiency of retrieval tasks. Different labels or attributes provide different degrees of support in partitioning the case-base. It is, therefore, possible for users to provide considerable contextual information that may have little impact upon the retrieval process. Fortunately, there are many well-established algorithms for determining the efficiency of partitioning in a case-based system. These have guided the development of NaCoDAE and the system supports a number of optimisation techniques. These enable designers to suggest means of tailoring the system to support common retrieval tasks so that users are led to exploit more efficient search strategies. We have not explored whether these approaches can be extended from more conventional applications of case-based reasoning to support more "efficient" and directed access to incident data.
6.3 Decision Support
Case-based reasoning systems were developed to help people identify previous situations that match aspects of a current problem. They were also developed to provide guidance on how to solve problems and make decisions. Previous sections have described the explicit support that NaCoDAE provides for the association of remedial actions with each case in the system. We have not, however, used this approach in our work with the ASRS datasets. Such an enhancement would be straightforward to implement. It has not been done because there is little or no information about such responses within the existing ASRS reports. If this data were to be made available then regulators and analysts could use the case-based retrieval facilities of NaCoDAE to ensure that they respond to situations in a consistent manner. It would also be possible to encode the outcome of the remedial action. Users could then determine what the remedial action was and whether or not it had been successful. This supports the long-term objective of avoiding previous failures by helping analysts to identify situations where particular actions did not resolve an anomaly. Without such assistance, there is a danger that the system would consistently advocate the wrong intervention.
7. Conclusions
Incident reporting systems can be used to detect problems before they result in an accident. They can also be used to strengthen the defences that lead to the detection and resolution of potential problems. Unfortunately, there are also significant limitations with these schemes. In particular, it can be difficult to identify similar cases amongst the thousands of reports that are submitted to many international schemes. Traditional databases offer little support here. Query formation can defeat even skilled analysts. As a result many of these systems yield results that have poor precision and low recall values. Similarly, free-text search engines have technical limitations that may make it difficult to identify incidents in which certain causes were NOT a factor. This paper has, therefore, argued that alternative techniques must be developed to support the indexing and retrieval of similar cases from within the growing body of evidence in large-scale incident reporting schemes. In particular, we have shown how case-based reasoning techniques can be extended from the domain of decision support to help analysts retrieve information about previous incidents. The US Navy’s Conversational Decision Aids Environment (NaCoDAE) has been used to illustrate this argument. It has been applied to different datasets from the US Aviation Safety Reporting System using two different approaches. The first was based on a classification that was part of the FAA’s reporting process. The second was based on the more general Eindhoven classification method. Initial results have been reported and directions for further research have been identified.
Acknowledgements
Thanks are due to the members of the Glasgow Accident Analysis Group and the Glasgow Interactive Systems group who provided valuable help and encouragement with this research. In particular, Peter McElroy helped with the application of NaCoDAE to parts of the ASRS database. Thanks are also due to David Aha and the US Naval Research Laboratory, Washington DC who provided access to the NaCoDAE system.
References
D. Aha, L.A. Breslow and H. Munoz-Avila, Conversational Case-Based Reasoning. Journal of Artificial Intelligence (1999, to appear).
D. Busse and C.W. Johnson, Human Error in an Intensive Care Unit: A Cognitive Analysis of Critical Incidents. In J. Dixon (editor) Proceedings of the 17th International Systems Safety Conference, The Systems Safety Society, Unionville, Virginia, United States of America, 138-147, 1999.
C.W. Johnson and M.D. Dunlop, Subjectivity and Notions of Time and Value in Information Retrieval, Interacting with Computers, (10): 67-75, 1998.
C.W. Johnson, A First Step Towards the Integration of Accident Reports and Constructive Design Documents. In M. Felici and K. Kanoun and A. Pasquini (eds), Computer Safety, Reliability and Security: Proceedings of 18th International Conference SAFECOMP'99, 286-296, Springer Verlag, 1999.
M. Lenz, B. Bartsch-Sporl, H.-D. Burckhard and S. Weiss (eds.), Case-Based Reasoning Technology: From Foundations to Applications, Springer Verlag, Berlin, 1998.
C. Owens, Integrating Extraction and Search. In J.L. Kolodner (editor) Case-based Learning. Kluwer, London, 1993.
A. Ram, Indexing, elaboration and refinement: Incremental learning of explanatory cases. In J.L. Kolodner (editor) Case-based Learning. Kluwer, London, 1993.
J. Rasmussen, Skill, Rules, Knowledge: Signals, Signs and Symbols and Other Distinctions in Human Performance Models. IEEE Transactions on Systems, Man and Cybernetics (SMC-13)3:257-266, 1983.
J. Reason, Managing the Risks of Organisational Accidents, Ashgate, Aldershot, 1998.
T. van der Schaaf, PRISMA: A Risk Management Tool Based on Incident Analysis. Proceedings of the International Workshop on Process Safety Management and Inherently Safer Processes, October 8-11, Orlando, Florida, 242-251, 1996.
S. Staender, M. Kaufman and D. Scheidegger, Critical Incident Reporting in Anaesthesiology in Switzerland Using Standard Internet Technology. In C.W. Johnson (editor), 1st Workshop on Human Error and Clinical Systems, Glasgow Accident Analysis Group, University of Glasgow, 1999.
W. van Vuuren, Organisational Failure: An Exploratory Study in the Steel Industry and the Medical Domain, PhD thesis, Technical University of Eindhoiven, Netherlands, 1998.