
Architectures for Incident Reporting
Chris Johnson
Department of Computing Science, University of Glasgow, Glasgow, G12 8QQ, UK. Tel: +44 (0141) 330 6053 Fax: +44 (0141) 330 4913http://www.dcs.gla.ac.uk/~johnson, EMail: johnson@dcs.gla.ac.uk
Abstract. Safety violations are rare events in any well-regulated industry. As a result, it can be difficult for interface designers to gather accurate information about their impact on human-machine interaction. Simulation provides a partial solution to this problem. However, it is difficult to determine whether these controlled scenarios accurately reflect potential ‘real-world’ failures. In contrast, incident reporting systems provide designers with direct information about the problems that occur during the operation of safety-critical systems. The perceived success of the FAA’s Aviation Safety Reporting System (ASRS) and the FDA’s MedWatch has led to the establishment of similar national and international schemes. These enable individuals and groups to report their safety concerns in a confidential or anonymous manner. The problems identified by such schemes can therefore, be used to identify the ‘real-world’ scenarios that can be examined in greater detail during subsequent simulation. The quality of the information that can be obtained from incident reporting systems is largely determined by the way in which these schemes are set up and maintained. Issues of anonymity, confidentiality and trust are critical to their long-term success. The way in which incident reports are filtered, investigated and reported are equally important. This paper, therefore, provides a brief overview of several different approaches that have been used to manage the operation of local, national and international systems.
Incident reporting schemes are increasingly being seen as a means of detecting and responding to failures before they develop into major accidents. For instance, part of the UK government’s response to the Ladbroke Grove crash has been to establish a national incident-reporting scheme for the UK railways [1]. The US Institute of Medicine’s has recently advocated the use of occurrence reporting systems as a primary means of combating the problem of report into human error in clinical systems [2]. A range of international treaties also recommends incident reporting systems. For example, the following recommendations come from the International Civil Aviation Organisation:
"(The assembly) urges contracting states to undertake every effort to enhance accident prevention measures, particularly in the areas of personnel training, information feedback and analysis and to implement voluntary and non-punitive reporting systems, so as to meet the new challenges in managing flight safety, posed by the anticipated growth and complexity of civil aviation"'.
(ICAO Resolution A31-10: Improving accident prevention in civil aviation)
"(The assembly) urges all Contracting States to ensure that their aircraft operators, providers of air navigation services and equipment, and maintenance organisations have the necessary procedures and policies for voluntary reporting of events that could affect aviation safety"
(ICAO Resolution A32-15: ICAO Global Aviation Safety Plan)
Incident reporting systems offer considerable insights into the problems of human-computer interaction in safety-critical applications. These insights often have an immediacy and directness that cannot easily be obtained under more constrained experimental conditions. For example, the following except comes from the UK Confidential Human Factors Incident Reporting system (CHIRP):
‘At the start of the Winter heavy maintenance programme, the company railroaded into place a computerised maintenance and integrated engineering and stores, planning and labour recording system. No training was given on the operational system only on a unit under test. Consequently we do not look at airplanes any more just VDU screens, filling in fault report forms, trying to order parts the system does not recognise, as the stores system was not programmed with (aircraft type) components (the company wanted to build a data base as equipment was needed).
When the computer informed us the 'C' check was complete and issued the CRS certification forms, I requested a task and certification report so I could convince myself that the work had in fact been recorded correctly. I was told this couldn't be done. After refusing to release the aircraft, the systems people managed to miraculously find one. The record had numerous faults, parts not recorded as being fitted, parts removed with no replacements, parts been fitted two or three times, parts removed by non-engineering staff, scheduled tasks not called-up by planning, incorrect trades doing scheduled tasks and certifying, and worst of all the record had been altered by none certifying staff after the CRS signatories had closed the work.
Quality Airworthiness Department were advised of these deficiencies and shown actual examples. We were advised by the management that these problems are being addressed but they are not, we still have exactly the same problems today. What am I to do without losing my job and career. In a closed community like aviation, troublemakers and stirrers do not keep jobs and the word is spread around. If I refuse to sign the CRS somebody who has not worked on the aircraft will be found to clear it (contravention of ANO?). (Air Navigation Order)'
[Editorial Comment]: The Company concerned was approached on this issue and responded that they had become aware of the difficulties being experienced. At the time this report was discussed they were just introducing a scheme whereby staff could report problems and get feedback on progress as part of their policy to encourage an open reporting culture. The certification procedures were specifically addressed. However, this would appear to have been another example of a complex computer system being introduced, or upgraded, without ensuring that the staff, who ultimately have to operate it, being consulted and trained properly at the outset.''[3]
Given the current proliferation of incident reporting systems and the many insights that they provide into safety-critical systems, it is surprising that there is little or no guidance about best practice that might guide the implementation of such different schemes [4]. This paper, therefore, provides a brief overview of a number of different ways in which incident reporting systems can be managed. It also identifies implications that each of these schemes has for the reporting of human-computer and human-machine interaction.
2. Simple Monitoring Architectures
Figure 1 represents the simplest architecture for an incident reporting system. A contributor submits a report based on the occurrence that they have witnessed or are concerned about. This submission process can be implemented using printed forms, by telephone calls, or increasingly using computer-based techniques. An external agency received the report and after assessing whether or not it falls within the scope of the system they will decide whether or not to publish information about the occurrence. The contributor and others with the same industry can then read the report and any related analysis before taking appropriate corrective actions.
Figure 1: A Simple Monitoring Architecture
This approach is typified by the Swiss Confidential Incident Reporting in Anaesthesia system (CIRS) [5]. A web-based form is used to submit an incident report to the managers of the system. Given the sensitive nature of these incidents, this is an anonymous scheme. The managers cannot, therefore, conduct follow-up investigations. However, they do perform a high-level analysis of this and similar events before publishing a summary on their web site. The following excerpt is taken from a CIRS incident report:
"During induction of inhalational anaesthesia (50% N2O/50% O2 / sevoflurane up to 8 Vol%) the patient did not reach a sufficient level of anaesthesia (there was only a superficial anaesthetic level with profound agitation which could be achieved although a sevoflurane oncentration up to 8 Vol% was used). The anaesthetic machine (Carba) was tested in the morning by the nurse and was found to be working correctly. During the event, the oximeter showed a FiO2 of near 75%, although a fresh gas mixture of 2 l N2O/min and 2 l O2/min. was choosen and could be seen on the rotameters. Surprisingly, the ventilation bag of the circle-circuit didn't collapse during inspiration and the boy didn't pass the excitation phase of the induction. An anaesthetic gas analyzer was not used. Because there must have been a surplus of fresh gas, the machine was checked again and the problem was found: this type of old anaesthetic machine has a oxygen flush button, which MUST TURNED ON AND MUST BE TURNED OFF AFTER USE. So, during checking the machine in the morning, the O2-flush button was tested, but not completely turned off again, so that the bypassed oxygen diluted the sevoflurane and the fresh gas mixture. Correcting this problem, the anaesthetic was completed successfully and with no further problem. The saturation of the patient was never below 97%." [5]
There are a number of limitations with the architecture shown in Figure 1. In particular, this simple monitoring approach simply provides a means of disseminating information about previous failures. There are no guarantees that individual organisations will take any necessary corrective actions. Similarly, there is a danger that different institutions will respond to the same incident in different ways. This inconsistency creates the opportunity for future failures if an organisation fails to correctly safeguard the system. A further problem is that this approach does not provide any means of determining whether reports were accurate or not. This creates potential dangers because a report may omit necessary information about the causes of an incident. As a result, other organisations might respond to the symptoms rather than the underlying problems that lead to an occurrence. As most of these systems are truly anonymous, it can be difficult or impossible for the managers of the scheme to identify whether any local, contextual factors contributed to an incident.
As with all of the architectures presented in this paper, there exist a number of variations that have been used to structure existing systems. For instance, the US Food and Drug Administration's Manufacturer and User Facility Device Experience Database (MAUDE) cuts out the external agency and enables individuals to report directly to the regulator. These reports are then posted on the FDA’s web site. If the incident is considered serious enough then the regulator may intervene through a product recall or amendment notice. The following citation illustrates the sort of software related incidents that are reported to this system:
"For approximately three weeks user hasn't been able to archive patient treatments due to software error. (The) facility has attempted to have company fix system in person but has only been successful at having company try by modem but to no avail." ([6], Report Number 269987).
This illustrates a number of important points about the human-computer interaction issues that are reported to schemes such as MAUDE. Firstly, reports often deal with maintenance and installation problems not simply difficulties during the operation of the embedded software. In this case, the report reveals the irritation that the users felt when the company attempted to fix the problem over a modem rather than in person. Only after this failed did they contact the FDA. Secondly, reports often reveal the deeper sense of frustration that can arise when computer-based systems fail to function as intended or when repair actions are attempted but "to no avail".
Figure 2 provides a high-level view of what we have terms the ‘regulated monitoring’ architecture for incident reporting. This is very similar to the approach described in the previous section. However, in this approach the external agency that received the contribution can go back and ask further questions to refine their understanding of an occurrence. Once they are clear about what has taken place, they produce a summary report that, typically, does not reveal the identity of their contributor. This summary is then placed before management and regulators who are responsible for identifying corrective actions. They must also determine whether those corrective actions can be implemented, again typically using the ALARP principle advocated by the UK HSE. The reporting agency will then receive a report on corrective actions that can then be communicated back to the original contributors and their colleagues through journal or newletter publications.
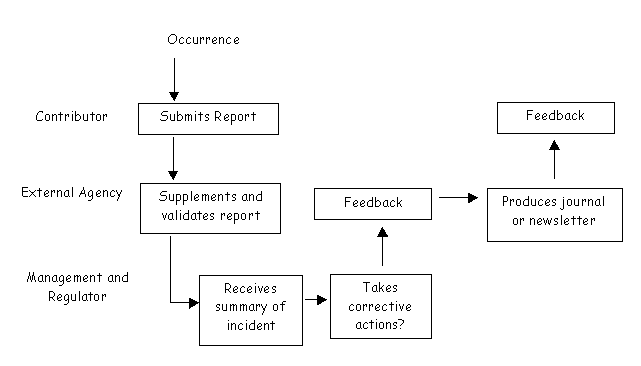
Figure 2: Regulated Monitoring Reporting System
The Confidential Incident Reporting and Analysis System (CIRAS) is a good example of an incident reporting scheme that implements the high-level architecture illustrated in Figure 2. This receives paper-based forms from Scottish train drivers, maintenance engineers and other rail staff. A limited number of personnel are responsible for processing these forms. They will conduct follow-up interviews in-person or over the telephone. These calls are not made to the contributor's workplace for obvious reasons. The original report form is then returned to the employee. No copies are made. CIRAS staff type-up a record of the incident and conduct a preliminary analysis. However, all identifying information is removed from the report before it is submitted for further analysis. From this point it is impossible to link a particular report to a particular employee. The records are held on a non-networked and ‘protected’ database. This data itself is not revealed to industry management. However, anonymous reports are provided to management at three monthly intervals. This concern to preserve trust and protect confidentiality is emphasised by the fact that a unit within Strathclyde University employs the personnel who process the reports rather than the rail operators.
The FAA's Aviation Safety Reporting System provides a further example of the architecture illustrated in Figure 2. NASA plays the role of the external reporting agency. Feedback is provided through a number of publications, such as the Callback newsletter and the DirectLine journal. The following report illustrates the types of incidents that are reviewed in these publications. It also illustrates the mix of editorial comment and verbatim report that characterise most of these publications. An important point strength of this approach is that it provides a measures assessment of several incidents through the editors’ analysis. It also enables staff to read an explanation of an incident through the words of their colleagues:
Editorial comment: Early versions of Traffic Alert and Collision Avoidance System (TCAS) II equipment displayed some hardware and software anomalies. The reliability of TCAS equipment has improved considerably, but there continue to be some problems -- as this recent report illustrates:
`Climbing through 1,200 feet [on departure] we had a TCAS II Resolution Advisory (RA) and a command to descend at maximum rate (1,500 to 2,000 feet per minute). [The flight crew followed the RA and began a descent.] At 500 feet AGL we leveled off, the TCAS II still saying to descend at maximum rate. With high terrain approaching, we started a maximum rate climb. TCAS II showed a Traffic Advisory (TA) without an altitude ahead of us, and an RA [at] plus 200 feet behind us... Had we followed the TCAS directions we would definitely have crashed. If the weather had been low IFR, I feel we would have crashed following the TCAS II directions. At one point we had TCAS II saying 'Descend Maximum Rate,' and the GPWS (Ground Proximity Warning System) saying 'Pull Up, Pull Up.' [The] ATC [Controller] said he showed no traffic conflict at any time.' [7]
Again there are a number of limitation with the high-level architecture shown in Figure 2. These do not stem principally from the problems of accessing more detailed causal information, as was the case with simple monitoring architectures. In contrast, they stem from the additional costs and complexities that are introduced by external reporting agencies. In particular, it can be difficult to preserve an independent but co-operative relationship between the organisation’s management and a reporting agency. This relationship can become particularly strained when the agency is responsible for identifying corrective or remedial actions that the management must then implement. As mentioned above, the ALARP principle is often used to justify resource allocation. The subjective nature of this approach can lead to conflicts over the priority allocated to many remedial actions. There is also a danger that these schemes will resort to low-cost reminders [8]. In consequence, many schemes operate on a smaller-scale, more local level. These schemes rely upon the same individuals to both collect the data and take immediate remedial actions.
Figure 3 illustrates the architecture that typifies many locally operated, incident-reporting systems. In many ways, these schemes were the pioneers of the larger more elaborate systems that have been mentioned in the previous sections. Individual sponsors either witness other schemes or independently decide to set up their own. Staff are encouraged to pass on incident reports to them. Typically, this is in a confidential rather than an anonymous fashion. Even if the forms do not ask for identification information it is often possible for the sponsors to infer who is likely to have submitted a form given their local knowledge of shift patterns and working activities. The sponsors can supplement the reports from their own knowledge of the procedures and practices within a unit. This enables them to analyse and validate the submission before passing a summary to their management. In contrast to other architecture, however, they are in a position to take direct remedial action. This is, typically, published in a newsletter. These publications not only provide feedback, they are also intended to encourage further submissions.

Figure 3: Local Oversight Reporting System
Local oversight architectures are illustrated by one of the longest running medical incident reporting systems. David Wright, a consultant within the Intensive Care Unit of an Edinburgh hospital, established this system over ten years ago [9]. The unit has eight beds at its disposal with approximately three medical staff, one consultant, and up to eight nurses per shift on the ward. . David Wright receives each report. They are then analysed with the help of a senior nurse. Any necessary corrective actions are instigated by them. Trust in the sponsor of this system is a primary concern, given the relatively close-knit working environment of an intensive care unit. The success of the system depends upon their reputation and enthusiasm. The extent of his role is indicated by the fact that very few reports are submitted when David Wright is not personally running the system.
The following incident was not reported to the Edinburgh system, mentioned above. However, it is typical of the incidents that are reported to many local systems. They provide a valuable insight into problems in the particular practices and procedures that are followed within an organisation. They also provide more general insights into the precursors of human error involving computer-controlled devices:
"During a coronary bypass graft procedure, an infusion controller device delivered a large volume of a potent drug to the patient at a time when no drug should have been flowing. Five of these microprocessor-based devices were set up in the usual fashion at the beginning of the day, prior to the beginning of the case. The initial sequence of events associated with the case was unremarkable. Elevated systolic blood pressure (> 160 torr) at the time of the sternotomy prompted the practitioner to begin an infusion of sodium nitroprusside via one of the devices. After this device was started at a drop rate of 10/min, the device began to sound an alarm. The tube connecting the device to the patient was checked and a stopcock (valve) was found to be closed. The operator opened the stopcock and restarted the device. Shortly after the restart, the device alarmed again. The blood pressure was falling by this time, and the operator turned the device off. Over a short period of time, hypertension gave way to hypotension (systolic pressure <60 torr). The hypotension was unresponsive to fluid change but did respond to repeated boluses of neosynephrine and epinephrine. The patient was placed on bypass rapidly. Later the container of nitroprusside was found to be empty; a full bag of 50mg in 250ml was set up before the case". [10]
The experienced physicians who had set up this device had assembled it so that it allowed a free flow of the drug into the patient once the physical barrier of the stopcock was removed. The device was started but there was no flow of the drug because the stopcock was closed and so a visual and an auditory alarm were presented. When the stopcock was opened, the device again failed to detect any drops of the drug being administered and the same alarms were presented. In this case, the device could not detect drops being administered because the drug was passing freely into the patient. The blood pressure dropped and so the physician shut-down the device. However, this did not prevent the continued flow of the drug. Such incidents emphasise the more general human factors observation that we cannot isolate our ability to perceive an alarm from our ability to detect the additional information that is necessary to diagnose the causes of the alarm.
The strengths and weaknesses of such local systems are readily apparent. The intimate local knowledge and direct involvement with the contributors makes the interpretation and analysis of incident reports far easier than in other systems. However, it can be difficult to replace key personnel and sustain confidence in the system. It can also be difficult to drive through deeper structural or managerial changes from local systems. Individual sponsors often lack the necessary authority (or resources) to instigate such responses. As a result they often ‘target the doable’. Similarly, it can be difficult to co-ordinate the efficient exchange of date between local systems to get a clearer overview of regional, national and even international trends.
3. Gatekeeper Architecture
Figure 4 illustrates the architecture of several national incident-reporting systems. The increased scale of such systems usually implies the greater degree of managerial complexity apparent in this framework. The contributor submits a report to their local manager. They may then take some initial remedial actions and then passes the form to a ‘gatekeeper’. They register the report; in any national system there is a danger that individual contributions may be lost or delayed. The ‘gatekeeper’ has this name because they must determine whether the occurrence is important enough to allocate further analytical and investigaory resources. If this decision is made then they will delegate the report to another unit within the organisation that is responsible for the aspect of the system that was most directly affected by the occurrence. The report is passed to a handler within this service department and they attempt to identify means of resolving any potential problems. Feedback is then provided to the contributor via their local manager. This approach is, typically, confidential or open rather than anonymous.

Figure 4: Gatekeeper Reporting System
.
This approach is exploited by the Swedish Air Traffic Control system. It is unusual in that it encourages the open reporting of a wide range of potential and observed failures. The definition of an ‘occurrence’ includes all forms of human, operational and technical failures even including incidents such as a failure of a light bulb. All reports are handled centrally by a number of specially trained gatekeepers who are responsible for filtering the reports and then passing them on to the relevant departments for action. These individuals must be highly trained both in the application domain of air traffic control but also in the technical problems that lead to system failures. However, because all occurrence reports pass through their offices they gain a detailed understanding of both operator behaviour and system performance. The gatekeepers, therefore, are in a position to provide valuable information both to training directors but also to the risk assessments that guide future investment decisions. The following quotation illustrates the insights that can be obtained from the gatekeepers who monitor incidents as they are received by the system. The opening paragraph readily reveals the overview that the analyst has of common features in many different occurrences:
"Some reporters continued with an operation even when something didn't look right, or was blatantly wrong. Flight crews also admitted to failing to request a tug to get into, or out of, a tight parking place. The latter two problems may have been responses to schedule pressure or to demand for on-time performance, also mentioned by many flight crew members as an underlying cause of incidents. These and other sources of distraction also caused a marked reduction of cockpit coordination and CRM skills. A plane's rear airstairs received damage when the crew became distracted by multiple demands, and failed to act as a team:
"[This incident was caused by] distractions in the cockpit, plus a desire to operate on schedule. There were several conversations going on from inside and outside the aircraft.
Raising the airstairs is a checklist item... backup is another checklist item which requires the Second Officer to check a warning light. No one noticed the light. The pushback crew consisted of 2 wing observers plus the individual in the tug...all failed to observe the rear stairs.''([11], #264692)
The gatekeepers are an important strength of the system shown in Figure 4. They are responsible for filtering reports and allocating remedial actions. This centralisation ensures a consistent analysis and response. However, they are a critical resource. There is a risk that they may act as a bottleneck if incidents are not handled promptly. This is particularly important because delays can occur while reports are sent from outlying areas to the gatekeeper’s central offices. The Swedish system has addressed many of these criticisms by adopting a range of computer-based systems that keep safety managers and contributors constantly informed about the progress of every incident report. However, there remains the danger for many of these systems that any omissions in the training of a gatekeeper can result in incorrect decisions being made consistently at a national level.
Figure 5 provides an overview of an alternative architecture for a national system. Rather than have a central gatekeeper who decides whether an incident falls within the scope of the system, this approach relies upon a more decentralised policy. Any of the personnel involved in the system can decide to suspend an investigation providing that they justify their decision in writing and pass their analysis to the safety management group who monitors the scheme. As can be seen, contributors pass their reports to their supervisors. This is important because in many industries, such as air traffic control, the individuals who are involved in an incident will often be relieved of their duties. A sense of guilt can often affect their subsequent performance and this can endanger further lives. In national systems, it is often common to provide an alternative submission route through an independent agency in case a report is critical of the actions taken by a supervisor.
The supervisor takes any immediate actions that are necessary to safeguard the system and informs the safety management group if the incident is sufficiently serious. The safety management group may then commission an initial report from a specialist investigation unit. They may also decide to provide an immediate notification to other personnel about a potential problem under investigation. These investigators may call upon external experts. Depending on the conclusions of this initial report they may also be requested to produce a final report that will be communicated back to the safety management group. In a number of these systems, such as the Australian aviation reporting system, these reports are issued to the original contributors who can append any points of further clarification. The safety management group is then responsible for communicating the findings and for implementing any recommendations following discussions with the regulatory authorities.

Figure 5: Devolved Reporting System
Figure 5 illustrates the complexities involved in organising nation and international reporting systems. It depends upon the co-ordination and co-operation of many different individuals and groups. However, such architectures are necessary when the problems of scale threaten to overwhelm systems based on the approach illustrated in Figure4. The problem with this system is that there is a greater chance of inconsistency because different staff determine how an occurrence is to be reported and investigated. Different supervisors may have different criteria for what constitutes an occurrence that should be passed on for further investigation. Most European air traffic control service providers have tackled this problem by publishing exhaustive guidelines on what should be reported. These guidelines are distributed to all personnel and are addressed during the training of control staff. The following quotation provides a concrete illustration of one such incident that stemmed from a communications failures. As with the previous incidents described in this paper, it again illustrates how incident reporting systems provide a rich source of information about failure in human-machine, human-computer and human-human interactions. Heathrow air traffic control were using Runway 27 Right (27R) for take off and Runway 27 Left (27L) for landing. There was one Departures officer coordinating traffic leaving from 27R and another Arrivals officer working with aircraft arriving on 27L. The Departures officer was undergoing training with a Mentor. When one aircraft (SAB603) initiated a missed approach. The Departures officer informed the Arrivals officer of a potential conflict with AFR 813. However, Departures did not inform the Arrivals officer of another aircraft BAW 818 that was also taking off at that time:
"The incident occurred when the weather at LHR (London Heathrow) deteriorated to conditions below that required by SAB (Sabena) 603 on approach. In consequence, the commander initiated a standard missed approach. Air Arrivals saw the aircraft climbing, acknowledged the missed approach to the crew and activated the missed approach alarm. He also informed his colleague, Air Departures, of the manoeuvre and received the information that AFR (Air France) 813 was airborne on a 'Midhurst' SID (Standard Instrument Departure) and that AFR 813 would be turned onto a westerly heading. However, he neither saw nor was informed that another aircraft, BAW (British Airways) 818, was also just taking off on a 'Brookmans Park' SID. Based on the information that he had received, Air Arrivals turned SAB 603 to the right to achieve maximum separation with AFR 813 and also to minimise any disruption to the latter aircraft's flightpath. This resulted in SAB 603 and BAW 818 coming into close proximity to each other. Air Departures failed to inform Air Arrivals of all the aircraft on departure at the time of the missed approach ecause she did not consider BAW 818 as a confliction. This omission was apparently endorsed by the Mentor since he failed to amplify the information passed. Although Air Departures was sitting in the controller's position, the Mentor retained overall responsibility for the duty."[12]
Such incidents are instructive because they typify the dual nature of group interaction in many incidents. On the one hand, the Arrivals and Departures officers created the conditions that led to the incident by failing to ensure that they were both aware of the potential conflicts. On the other hand, effective intervention by the Mentor helped to ensure that an incident did not develop into an accident. It is important not to forget that the number of failures that are detected and resolved through effective teamwork will far out-strip the number of reported incidents of team-based failure.
5. Conclusions and Further Work
This paper has identified a number of different architectures for incident reporting systems. It has been argued that each approach will have a different impact on the sorts of occurrences that are submitted by operators. These differences can be observed in a number of existing systems. However, the precise relationship between the choice of reporting architecture and the quality of the information obtained remains a subject for future research. This raises a number of methodological concerns. In particular, it may not be ethical to run controlled tests in which some operators contribute information about safety-related incidents to a system that is different from those offered to their colleagues.
It is important to emphasise that this paper has avoided normative arguments about the absolute value of the different architectures that have been presented. This is entirely deliberate. As suggested in the previous paragraph, we know very little about the impact of these different management structures. In consequence, it is difficult to be confident in any comparative analysis. Tools and techniques for performing such comparisons are urgently needed as incident reporting systems continue to proliferate in many different industries.
REFERENCES
[1] J.D. Davies, L.B. Wright, E. Courtney and H.Reid, Confidential Incident Reporting on {UK} Railways: The {CIRAS} System. Cognition, Technology and Work (in press).
[2]L. Kohn, J. Corrigan and M. Donaldson, To Err Is Human: Building a Safer Health System, Committee on Quality of Health Care in America, US Institute of Medicine, National Academy Press, Washington DC, United States of America, 1999.
[3] Confidential Human Factors Incident Reporting Programme (CHIRP), Computer Aided? In Feedback, Number 49, January 1999. Available on: http://www.chirp.dircon.co.uk/air_transport/FB49.htm
[4] W. van Vuuren, Organisational Failure: An Exploratory Study in the Steel Industry and the Medical Domain, PhD thesis, Technical University of Eindhoiven, Netherlands, 1998.
[5] S. Staender, Critical Incidents Reporting System (CIRS): Critical Incidents in Anaesthesiology, Department of Anaesthesia, University of Basel, Switzerland, 2000. Available on: http://www.medana.unibas.ch/cirs/
[6] Centre for Devices and Radiological Health, Manufacturer and User Facility Device Experience Database (MAUDE, US Food and Drug Administration. 2000. Available on: http://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfMAUDE/search.CFM
[7] V.J. Mellone , TCAS II: Genie Out of the Bottle. DirectLine, Number 4, US Aviation Safety Reporting System, NASA Ames Research Centre, California, United States of America. June 1993. Available on: http://asrs.arc.nasa.gov./directline_issues/dl4_tcas.htm
[8] C.W. Johnson, Don't Keep Reminding Me: The Limitations of Incident Reporting, In Proceedings of HCI Aero'2000, European Institute of Cognitive Science and Engineering (EURISCO), Toulouse, France, Accepted and to appear, 2000.
[9] D. Busse and C.W. Johnson, Human Error in an Intensive Care Unit: A Cognitive Analysis of Critical Incidents. In J. Dixon (editor) 17th International Systems Safety Conference, Systems Safety Society, Unionville, Virginia, USA, 138-147, 1999.
[10] R.I. Cook and D.D. Woods, Operating at the Sharp End. In M.S. Bogner (ed) Human Error in Medicine, 255-310, Lawrence Erlbaum Associates, Hillsdale, NJ, United States of America, 1994.
[11] R. Chamberlin, C. Drew, M. Patten and R. Matchette, Ramp Safety, DirectLine Number 8, Aviation Safety Reporting System, NASA Ames Research Centre, California, United States of America, June 1996. Available on: http://asrs.arc.nasa.gov./directline_issues/dl8_ramp.htm
[12] Air Accidents Investigations Branch Report on an incident near London Heathrow Airport on 27 August1997 - AIRPROX (C) : Boeing 737-200 and Boeing 757, Department of Transport, Her Majesty's Stationery Office, London, United Kingdom. Report 5/98, 1998.