1.
a) Failure Modes, Effects and Criticality Analysis (FMECA) defines a risk priority number to be the product of a severity index, an occurrence index and a detection index. Briefly explain why it is important to consider each of these terms during any assessment of failure modes.
[3 marks] (Seen problem/bookwork)
The severity index is used to denote the possible consequences of a failure mode. The occurrence index indicates the relative frequency of that failure. So, for example, a low cost, high frequency failure may be just as significant as a high cost but very low frequency failure. The detection index is necessary because a failure mode may continue to have an adverse effect on the safety of the system until it is detected and rectified.
b) Identify three major problems that can prevent the use of risk priority numbers being applied to modes that relate to software failures.
[5 marks] (Seen/unseen problem)
There are several different answers to this -
- The occurrence index for reliable systems is likely to represent an extremely small probability. This is likely to be a crude approximation based on limited empirical evidence.
- Detection factors are difficult to predict because they depend upon the vigilance and working practices or maintenance standards of organisations over the lifetime of the system.
- The severity index will be subjective - the consequences of a component failure to the overall functioning of a complex system can be hard to anticipate.
c) John Musa’s work at Bell labs led to the definition of the following equation:
lambda_0 = K x P x W_0
where:
- lambda_0 is a failure rate for software systems
- k is a constant that accounts for the dynamic structure of the program and the varying machines (e.g., k = 4.2E-7).
- p is an estimate of the number of executions per time unit (ie, p = r/SLOC/ER).
- r is an average instruction execution rate, determined from the manufacturer or benchmarking and is a constant value.
- SLOC is the number of source lines of code (not including reused code).
- ER is an Expansion ratio. It is a constant that reflects properties of particular programming languages (e.g., Assembler, 1.0; Macro Assembler, 1.5; C, 2.5; COBAL, FORTRAN, 3; Ada, 4.5).
- W_0 is an estimate of the initial number of faults in the program. This can be calculated using: w0 = N x B or a default of 6 faults/1000 SLOC can be assumed.
- N is the total number of inherent faults. This is an estimate based on judgement or past experience.
- B is the fault to failure conversion rate; that is the proportion of faults that become failures. Proportion of faults not corrected before the product is delivered. Assume B = .95; i.e., 95% of the faults undetected at delivery become failures after delivery.
Briefly explain why the terms in the Musa formula were originally thought to provide a good indication of software reliability.
[12 marks] (Unseen problem)
This question is deliberately open-ended - there are many terms in the Musa formulae that can be criticised but the question is asking them to think why they were every believed in the first place. For instance, many would now argue that the reliability of different programmers and different development techniques is probably more of a factor than the terms in this equation. However, some support can be provided for the language expansion ratio. Similarly, empirical results within a company or team might be used to validate the 6 faults per 1000 SLOC that is used as a default value for w_0. There are certain particular problems. For instance, the definition of SLOC ignores reused code and yet experience has shown us that re-used code is a primary source of failure in software systems. The course has covered the Ariane 5 accident and the Lyons report in considerable detail so they should be aware of this.
2.
(a) Briefly define what is meant by the term "situation awareness".
[3 marks] (Seen problem/bookwork)
Situation awareness is a term that is used to describe the users understanding of the present state of their system and their ability to use that information to predict the future state of the system. This in turn helps them to accurately plan their future interaction.
b) Why is situation awareness likely to be a significant problem for safety-critical applications such as Air Traffic Control.
[5 marks] (Unseen problem)
Applications that involve several different operators and several different information sources can impose considerable strains on users. For example, it can be difficult to predict and synchronise information from these different sources. In the air traffic control context, there are established procedures that crews and ATC officers must follow so that others involved in the system can predict what they are likely to do. There are also extensive training procedures, for instance in CRM, that are used to help people determine the current state of the airspace/colleagues and therefore make accurate predictions about future interaction.
c) The following diagram presents Wickens and Flach’s model of information processing.
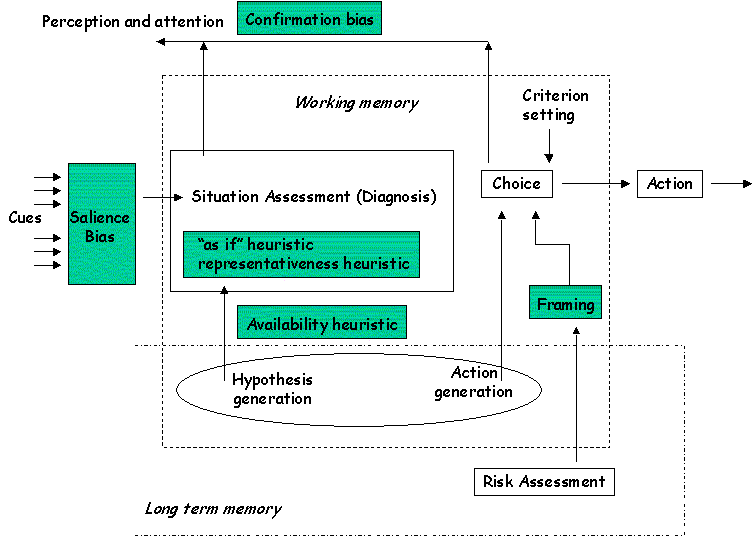
Use this model to explain the following excerpt from the FAA’s Aviation Safety Reporting System.
"Late night training flight...We were going out to make a 180 degree turn and land. The aircraft is equipped with an Enhanced Ground Proximity Warning System. I vectored the student on a modified procedure turn. I put my head down to get some reference data and heard the ground proximity warning, "Caution, terrain." I took over the controls and performed our escape manoeuvre and gave the jet back to the student. The student allowed the jet to descend again while my head was down. Again the ground proximity [warning] went off. I did our escape manoeuvre again and flew the aeroplane to the final approach course and let the student land. There were only 3 of us on board. Another student was in the jump seat. I asked them if they saw the terrain on the enhanced display and they said yes. They thought I would tell them when to turn… I should not have looked away while in that phase of flight with new students unfamiliar with the area." (ASRS Callback, Issue 237 March 1999)
[12 marks] (unseen problem)
Again there are a variety of answers here - the main idea is that the pilot lost situation awareness because they failed to predict the students? actions and therefore, failed to anticipate the EGPWS warnings. The pilot?s hypothesis generation in the model was flawed and they made an incorrect choice of action when they returned to the reference data. It is also possible to look at the confirmation bias side of the diagram and argue that the pilot did not attend to the manoeuvre because they believed that the student would react in the "correct" or anticipate fashion. As a result, the pilot acted "as if" the student understood their responsibilities and tasks after the first warning.
Other solutions could make similar arguments about the students loss of situation awareness on the basis of the pilots closing comments that the students were unfamilliar with the terrain that they were flying across.
3. (a) Briefly distinguish between permanent, transient and intermittent faults.
[3 marks] (seen problem/bookwork)
Intermittent faults: fault occurs and recurs over time. For example, poor wiring can lead to intermittent faults.
Transient faults: fault occurs but may not recur. For example, electromagnetic interference may cause transient faults.
Permanent faults: fault persists. For instance, physical damage to a processor is a permanent fault.
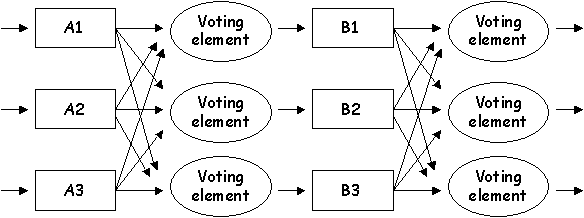
(b) Draw a diagram to illustrate the main features of triple modular redundancy. Use this diagram to explain how a multilevel, triple modular redundancy architecture can be used to improve the reliability of safety critical hardware.
[5 marks] (seen/unseen problem)
The following diagram illustrates the multi-level TMR solution. Students need only produce a single level of this diagram. The key points are that voting elements are used to compare the outputs at each level. Values are only passed on if the elements agree. This approach is vulnerable to 2+ modules failing and will not cope with replicated flaws in multiple modules. Multilevel TMR is too complex and costly for the modest benefits that it offers and so is not used in many practical applications.
(c) Use the following excerpt to briefly explain the main features that contribute to the reliability of the US Space Shuttle General Purpose Computer (GPC) architecture:
"Each computer in a redundant set operates in synchronized steps and cross-checks results of processing about 440 times per second. Synchronization refers to the software scheme used to ensure simultaneous inter-computer communications of necessary GPC status information among the primary avionics computers. If a GPC operating in a redundant set fails to meet two redundant synchronization codes in a row, the remaining computers will vote it out of the redundant set. Or if a GPC has a problem with its multiplexer interface adapter receiver during two successive reads of response data and does not receive any data while the other members of the redundant set do not receive the data, they in turn will vote the GPC out of the set. A failed GPC is halted as soon as possible."
(NASA Shuttle Public Technical Reference Material)
[12 marks] (unseen problem)
As with all of the final parts to these questions, I am trying to give first class students the scope to be more creative and analytical in the way that they answer questions about "real-world" systems. As before, therefore, there are a variety of solutions. The main focus here is on the use of redundancy to increase the level of assurance over the reliability of hardware. The opening sentence in the previous quotation was chosen because it creates a clear link back to solutions in the previous part about TMR. Here the redundant set cross-checks results in the same manner that a comparator can be used to check the output of TMR architectures. This not only applies to the computations performed by each element. Checks are also performed on the input received by each GPC through its interface adapter. In either case, if a difference is detected between one of the units and its peers in a redundant set then the single unit will be excluded as quickly as possible to prevent faults from propagating into subsequent computations.
The limitations of redundant approaches have been covered in class N/2-1 tolerances can be accepted. Any more and it will fail. This is significant if similar design/development flaws exist in more than one unit. Synchronisation problems can arise so that individual GPC?s are delayed before comparison or may even find themselves out of step etc.
- With reference to IEC61508 or DO-178B, argue for or against the statement that standards are both a necessary and a sufficient prerequisite for the development of safety-critical computer systems.
[20 marks]
There are many different answers to this. The intention of an essay question is to allow first class students to construct their own discussion and to allow other students to reproduce some of the material that I have already provided.
Key ideas behind the question include the distinction between necessary and sufficient. Standards are necessary to ensure that companies and individuals follow minimum approved practices. They are not sufficient unless supported by other practices that support a wider safety culture. This is particularly important when line management may have to preserve budgets in the face of changes to a project?s expenditure profile. For example, 61508 recognise that it is possible to apply recommended methods but still end up with an unsafe system if they are not applied in a rigorous manner.
In the course, we have focussed on some of the aims behind standardisation and certification but also the importance of ethics. It is possible to conform to a standard and yet also produce an unsafe system. For instance, if associated documentation does not reflect development practices or the final product. All of the professional codes (ACM, IEEE) include sections on individual responsibility in these situations.
Changes in operating environments or to the standards themselves may also mean that a system, which satisfied a set of requirements at one point in time, may fail to conform to those standards in the future. Some students may argue that many safety-critical systems have been successfully built without conforming to particular standards. If they choose to follow this line then they need to provide examples and to explain the long term problems that can arise as projects grow in scale and complexity.
[end]