
Software Support for Incident Reporting Systems in Safety-Critical Applications
Chris Johnson
Department of Computing Science, University of Glasgow, Glasgow, G12 8QQ, UK. Tel: +44 (0141) 330 6053 Fax: +44 (0141) 330 4913 http://www.dcs.gla.ac.uk/~johnson, EMail: johnson@dcs.gla.ac.ukAbstract. Incident reporting systems are playing an increasingly important role in the development and maintenance of safety-critical applications. The perceived success of the FAA’s Aviation Safety Reporting System (ASRS) and the FDA’s MedWatch has led to the establishment of similar national and international schemes. These enable individuals and groups to report their safety concerns in a confidential or anonymous manner. Unfortunately, many of these systems are becoming victims of their own success. The ASRS and MedWatch have both now received over 500,000 submissions. In the past, these systems have relied upon conventional database technology to support the indexing and retrieval of individual reports. However, there are several reasons why this technology is inadequate for many large-scale reporting schemes. In particular, the problems of query formation often result in poor precision and recall. This, in turn, has profound implications for safety-critical applications. Users may fail to identify similar incidents within national or international collections. This paper, therefore, shows how several alternative software architectures support incident report systems in safety-critical applications.
Incident reporting schemes are increasingly being seen as a means of detecting and responding to failures before they develop into major accidents. For instance, part of the UK government’s response to the Ladbroke Grove crash has been to establish a national incident-reporting scheme for the UK railways. At a European level, organizations such as Eurocontrol have been given the responsibility of establishing international standards for the reporting schemes that are operated by member states. In the United States, the Senate recently set up the Chemical Safety and Hazard Investigation Board to coordinate incident reporting throughout the chemical industries. The popularity of these schemes depends upon their ability to elicit reports from operators. This, in turn, depends upon individuals receiving the feedback that is necessary to demonstrate that their participation is both valued and worthwhile. People will only submit if they believe that their contributions will be acted on. In part this depends upon the confidentiality of the system. Individuals must not fear retribution providing that they are not reporting criminal activity. However, an effective response and individual participation also rely upon our ability to analyze and interpret the submissions that are made to incident reporting schemes.
In the past, most incident reporting schemes in safety-critical industries have operated at a local level. For instance, chemical and steel companies have developed proprietary systems that operate within their plants [1]. In the UK health service this has led to a situation where there are many different local schemes with no effective means of sharing data between hospitals. This situation is not as pathological as it might appear. Local schemes have the benefit that individual contributors can directly monitor the impact of their contributions on their working environment. The people maintaining these systems can also inspect the systems and environments in which incidents occur [2]. However, the disadvantages are equally apparent. There is a danger that the lessons learnt in one institution will not be transferred to other organizations. There is also a danger that individual incidents may appear as isolated instances of failure unless there is confirmatory evidence of similar incidents occurring on a national and international scale [3]. For all of these reasons there is now an increasing move towards national and international systems. Later sections will describe how this is introducing new problems of scale that can only be solved with software support.

Figure 1: FDA Incident Reporting Form for Medical Devices
Figure 1 provides an example of the forms that are used to elicit information about incidents, including software failures, in safety-critical industries. It illustrates the format that is used by the US Food and Drug’s Administrations MedWatch program. This particular form is intended for healthcare professionals to report incidents involving medical devices. As can be seen, this form only asks for rudimentary details about particular incidents. This is justified because the system is confidential and not anonymous. The operators of the MedWatch programme can, therefore, contact the respondents to elicit further information. Figure 2 presents two MedWatch reports that deal specifically with software "failures" in medical devices.
Access Number: M484728 Date Received: 12/13/93
Product Description:
BOEHRINGER MANNHEIM-HITACHI CLINICAL CHEMISTRY ANA
Manufacturer Code: BOEHMANN
Manufacturer Name:
BOEHRINGER MANNHEIM CORP., 9115 HAGUE ROAD, INDIANAPOLIS,
Report Type: MALFUNCTION Model Number: 911
Catalog Number: NI Product Code: JJC
Panel Code: CLINICAL CHEMISTRY Event Type: FINAL
Event Description: clinical chemistry analyzer erroneously printed out a value of >5 as the result of a lipase control, but transmitted the correct value of 39 to the laboratory's host computer. The software for the analyzer was evaluated by its mfr and was found to contain a software bug which caused the inappropriate printing of a qualitative parameter when the laboratory host computer and data printing accessed the qualitative data processing program at the same time. Software mfr has modified the software, and an evaluation of the revised software is in progress at this co. (*)
Access Number: M830568 Date Received: 09/25/95
Product Description: PRX SOFTWARE DISK Manufacturer Code: CARDPACE
Manufacturer Name:
CARDIAC PACEMAKERS, INC., 4100 HAMLINE AVE N, ST. PAUL, MN 55112
Report Type: MALFUNCTION Model Number: 2860
Catalog Number: NA Product Code: LWS
Panel Code: CARDIOVASCULAR Event Type: FINAL
Event Description: co received info from a field clinical engineer that while using software module during a demonstration with a non functional implantable cardioverter defibrillator, noted that two of the keys were mapped incorrectly. The field clinical engineer then changed to another software module, same model, serial number 006000. And experienced the same results. Corrective action: co has recalled and requested the return of affected revision 11.2 software modules and replaced them with the appropriate version. (*)
Figure 2: Examples of Software Failure from the FDA’s MedWatch Programme.
The records shown in Figure 2 are typical of the information that is lodged with incident reporting schemes. A number of categories are used to help index the data and to support subsequent statistical analysis. In the case of the MedWatch programme, this includes information about the particular types of devices that were involved, the Product Code. The classification information also includes the clinical area that the device was being used in, the Panel Code. Free text is also used to provide details about how the incident was detected and was resolved, the Event Description.
2. The Problems
Incident reporting systems have become victims of their own success. The FAA has maintained a consistently high participation rate in the ASRS since it was established in 1976. It now receives an average of more than 2,600 reports per month. The cumulative total is now approaching half a million reports. Medwatch, illustrated by Figures 1 and 2, was set up by the FDA as part of the Medical Devices Reporting Program in 1984. It now contains over 700,000 reports. These figures are relatively small when compared to the size of other data sets that are routinely maintained in many different industries. However, the safety-critical nature of these reports creates a number of unique problems that frustrate the development of appropriate software support.
2.1 Precision and Recall
Precision and recall are concepts that are used to assess the performance of all information retrieval systems. In broad terms, the precision of a query is measured by the proportion of all documents that were returned which the user considered to be relevant to their request to the total number of documents that were returned. In contrast, the recall of a query is given by the proportion of all relevant documents that were returned to the total number of relevant documents in the collection [3]. It, therefore, follows that some systems can obtain high recall values but relatively low precision. In this scenario, large numbers of relevant documents will be retrieved together with large numbers of irrelevant documents. This creates problems because the user must then filter these irrelevant hits from the documents that were returned by their initial request. Conversely, other systems provide high precision but poor recall. In this situation, only relevant documents will be returned but many other potential targets will not be retrieved for the user.
In most other areas of software engineering, the trade-off between precision and recall can be characterized as either performance or usability issues. In incident reporting schemes, these characteristics have considerable safety implications. For instance, low-recall systems result in analysts failing to identify potentially similar incidents. This entirely defeats the purpose of compiling national and international collections. More worryingly in a commercial setting it leaves companies open to litigation in the aftermath of an accident. Failure to detect trend information in previous incident reports can be interpreted as negligence. Conversely, low-precision approaches leave the analyst with an increasing manual burden as they are forced to continually navigate "another 10 hits" to slowly identify relevant reports from those that have no relation to their information needs. Again this can result in users failing to accurately identify previous records of similar incidents.
2.2 Data Abstractions and Dynamic Classifications
A number of further problems complicate the software engineering of tool support for incident reporting systems. In particular, incidents will change over time. The introduction of new technology and working practices creates the potential for different forms of hardware and software failure as well as different opportunities for operator "error". Any data abstractions that are used to represent attributes of incident reports must also be flexible enough to reflect these changes in incident classification schemes. This problem arises because the incident classification schemes that regulators use to monitor the distribution of events between particular causal categories are, typically, also embodied in the data abstractions of any underlying tool support.
There are two general approaches to the problems of developing appropriate data models for incident reports. The first relies upon the use of generic categories. These include "software failure" rather than "floating point exception" or "human error" rather than "poor situation awareness". These high-level distinctions are unlikely to be extended and refined over time. However, they also result in systems that yield very low precision. A query about "floating point exceptions" will fail if all relevant reports are classified as "software failures". Further problems arise if inheritance mechanisms are used to refine these high level distinctions. The addition of new sub-types, for instance by deriving "floating-point exceptions" from "software failures", forces the reclassification of thousands of existing reports.
The second approach that addresses the changing nature of many incidents is to develop a classification scheme that is so detailed, it should cover every possible adverse event that might be reported. To provide an illustration of the scale of this task, the US National Co-ordinating Council for Medication Error Reporting and Prevention produces a Taxonomy of Medication Errors. This contains approximately 400 different terms that record various aspects of adverse incidents. EUROCONTROL have developed a similar taxonomy for the classification of human "error" in incident reports. There is no such taxonomy for software related failures. This is a significant issue because retrieval systems must recognise similar classes of failures in spite of the different synonyms, euphemisms and colloquialisms that are provided in initial reports of "bugs", "crashes", "exceptions" and "run-time failures". There are further more general problems. In particular, if safety-critical industries accept detailed taxonomies then software tools may exhibit relatively poor recall in response to individual requests. The reason for this is that many existing classification systems are exclusive. As can be seen from Figure 2, incidents tend to be classified by single descriptors rather than combinations of terms. As a result, many incidents that stem from multiple systemic failures cannot easily be identified. There is also the related problem that national and international systems must rely on teams of people to perform the analysis and classification. This introduces problems of inter-classifier reliability. Systems that are based on a detailed taxonomy increase the potential for confusion and ultimately low recall because different classifiers may exhibit subtle differences in the ways in which they distinguish between the terms in the taxonomy.
There are two central tasks that users wish to perform with large-scale incident reporting systems. These two tasks are almost contradictory in terms of the software requirements that they impose. On the one hand, there is a managerial and regulatory need to produce statistics that provide an overview of how certain types of failures are reduced in response to their actions. On the other hand, there is a more general requirement to identify trends that should be addressed by those actions in the first place. The extraction of statistical information typically relies upon highly-typed data so that each incident can be classified as unambiguously belonging to particular categories, such as those described in the previous section. In contrast, the more analytical uses of incident reporting systems involve people being able to explore alternative hypotheses about the underlying causes of many failures. This, in turn, depends upon less directed forms of search. Unfortunately, most incident reporting systems seem to be focussed on the former approach. Relatively, few support these more open analytical activities.
Many incident reporting systems exploit relational database techniques. They store each incident as a record. Incident identifiers, such as the classified fields before the free text descriptions in figure 2, are used to link, or join, similar records in response to users’ queries. It is important to emphasize that many existing applications of this relational technology have significant limitations. They are, typically, built in an ad hoc manner using mass-market database management systems. The results are often very depressing. For example, Boeing currently receives data about maintenance incidents from many customer organizations. Each of these organizations exploits a different model for the records in their relational systems. As a result, the aircraft manufacturer must attempt to unify these ad hoc models into a coherent database. At present, it can be difficult or impossible for them to distinguish whether a bolt has failed through a design fault or through over torquing by maintenance engineers. Sam Lainoff recently summarized the problems of populating their relational database in the following way:
"There is no uniform reporting language amongst the airlines, so it’s not unusual to find ten different ways of referring to the same thing. This often makes the searching and sorting task a difficult proposition… The data we have won’t usually permit us to create more refinement in our error typing. But at times it will give us enough clues to separate quality problems, and real human error from pure hardware faults." [4].
This quotation illustrates a couple of points. Firstly, it identified the commercial importance of these problems within safety-critical industries. Secondly, it is indicative of the problems that people face when attempting to correctly assign values to the fields that are defined in relational databases. This problem stems from the diverse and changing nature of incident reports that was described earlier. However, this quotation does not reveal all of the problems that are created by relational approaches. In particular, it can be extremely difficult for people who were not involved in the coding and classification process to develop appropriate queries. One example query in a relational incident reporting system within the steel industry was expressed as follows:
$ SEL 1; USE EMP; INDEX SEV TO T1; SEL 2; USE DEPT;
INDEX SEV TO T2; SET REL EMP SEV; DISP NAME SEV ID DATE
Even professional software engineers fail to retrieve correctly indexed records using relational query languages such as SQL [5]. These findings are not significantly effected even when graphical and menu-driven alternatives are provided.
4. Solutions: Free-Text Retrieval and Probabilistic Inference
Information retrieval tools provide powerful mechanisms for indexing and searching large collections of unstructured data. They have supported numerous applications and are ubiquitous on the World Wide Web. It is, therefore, surprising that they have not been more widely adopted to support incident reporting systems. One explanation for this is that they cannot, in their pure form, be used to collate the statistics that are more easily extracted using relational systems. However, they avoid many of the problems associated with database query languages. In particular, they offer a range of techniques for exploiting semantic information about the relationships between the terms/phrases that appear in a document and the terms/phrases that appear in the users’ query. These techniques enable analysts to ensure that queries that include concepts such as "software failure" will also be associated with terms such as "Floating point exception" or "Null pointer error".
Information retrieval systems, typically, perform several indexing processes on a data set before it can be searched [6]. For instance, variations on Porter’s stemming algorithm can be used to unify terms such as "failure", "failing" and "failed". This preliminary analysis also includes the compilation of dictionaries that support query expansion. For example, "Numeric Error Exception" and "Floating Point Exception" occur in similar contexts but are not synonyms. As a result, they may not be grouped within standard thesauri. Programmers and analysts can, however, provide this semantic information so that a retrieval engine will locate both forms of incident in response to a user’s query about numeric software failures. These rather simplistic techniques are supported by more complex concept recognition. Information retrieval tools can exploit probabilistic information based on the relative frequencies of key terms [6]. The system can rank documents according to whether or not it believes that documents are relevant to a query. If a term such as "floating point exception" occurs in a query but is only used infrequently in the collection then those documents that do contain the term are assigned a relatively high probability of matching the query. This process of assigning probabilities can be taken one stage further by supporting relevance feedback. In this process, the user is asked to indicate which of the documents that the system proposed were actually relevant to their query. The probabilities associated with terms that occur amongst several of the documents that are selected can then be increased.
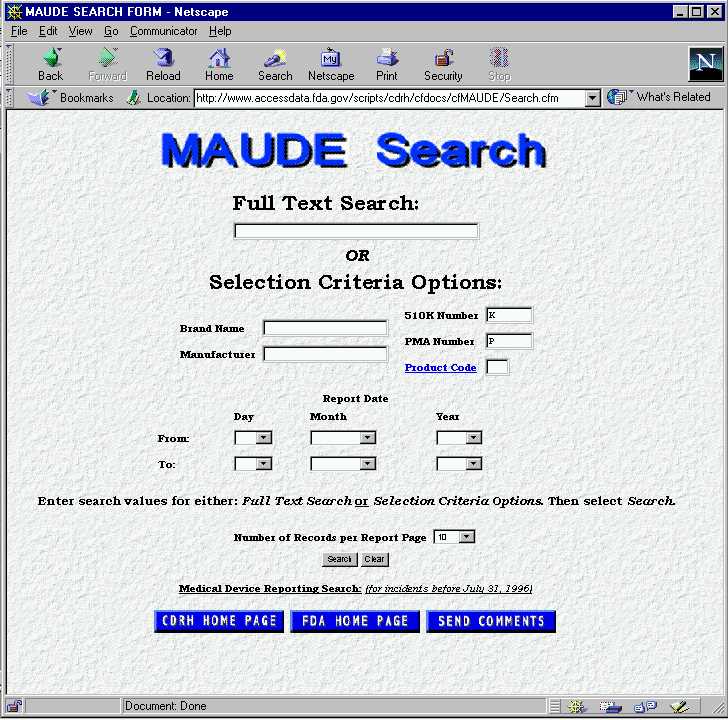
Figure 3: Integrating Information Retrieval and Relational Techniques
(http://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfMAUDE/Search.cfm)
Figure 3 illustrates how the FDA have recently exploited some of the techniques mentioned above in their medical devices reporting system. As can be seen, this system also retains the ability to exploit the fields that were encoded in earlier relational approaches mentioned in the previous section. Unfortunately, these approaches still have a number of disadvantages when providing software support for incident reporting schemes. In particular, it is still difficult to tune queries in retrieval engines and in relational databases to improve both the precision and recall of particular searches. As a result, it is entirely possible for users to issue queries that fail to find similar incidents or which return almost every report in a collection of well over half a million incidents.
5. Solutions: Conversational Search and CBR
Case Based Reasoning (CBR) offers a further alternative to information retrieval techniques and relational databases. In particular, conversational case based reasoning offers considerable support for the retrieval of incident reports within safety-critical industries. For instance, the US Naval Research Laboratory’s Conversational Decision Aids Environment (NaCoDAE) presents its users with a number of questions that must be answered in order to obtain information about previous hardware failures [7]. For instance, if a user inputs the fact that they are facing a power failure then this will direct the system to assign greater relevance to those situations in which power was also unavailable. As a result, the system tailors the questions that are presented to the user to reflect those that can most effectively be used to discriminate between situations in which the power has failed. NaCoDAE was initially developed to support fault-finding tasks in non-safety critical equipment such as printers. We have recently extended the application of this tool to help analysts perform information retrieval tasks in large-scale incident reporting systems, including the FAA’s ASRS. Figure 4 illustrates this application of the NaCoDAE tool. After loading the relevant case library, the user types in a free-text query into the "Description" field. This is then matched against the cases in the library. Each case is composed of a problem description, some associated questions and if appropriate a description of remedial actions. The system then provides the user with two lists. The first provides "Ranked Questions" that the system believes are related to the user’s original question. This helps to reduce the query formation problems that have been noted for other systems. The second "Ranked cases" list provides information about those cases that the system currently believes to match the situation that the user is confronted with. A particular benefit of this approach is that Stratified Case Based Reasoning algorithms can be used to ensure that questions are posed in a certain order. They can help to ensure that users move from general questions that partition the case base at a gross level to increasingly precise questions that may only yield specific cases in response to their interactive search [7].
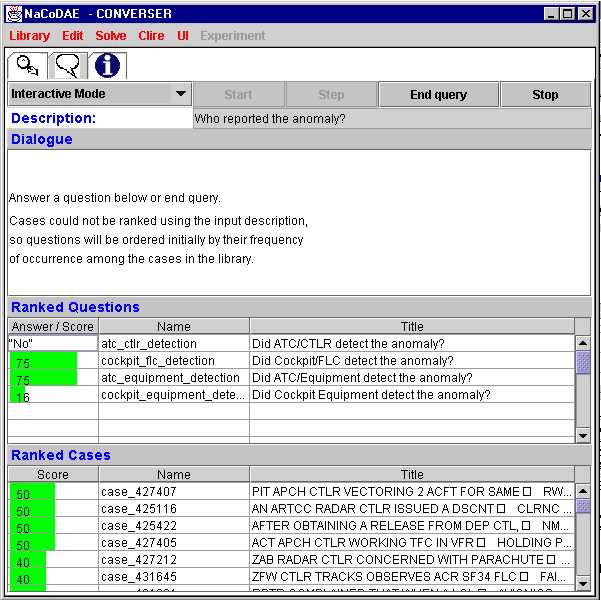
Figure 4: Using Conversational CBR to Support Incident Reporting
The previous paragraph indicates the critical nature of the questions that are encoded within the NaCoDAE system. Our study began by deriving these questions directly from the fields that are encoded in the MedWatch and ASRS systems. Users navigate the case base by answering questions about how the incident was resolved, what the consequences of the anomaly were, who identified the anomaly etc. If the user selected Cockpit/FLC as an answer to the question "Who detected the incident?" then all cases in which the flight crew did not detect the incident would be automatically moved down the list of potential matches. Each incident report only contains answers to some of these questions. For instance, the person submitting the form may not know how it was resolved. Once a set of similar cases has been identified, it can look for questions that can discriminate between those cases. For example, if some highly ranked cases were resolved by the Aircrew and others were resolved by Air Traffic Controllers then the system will automatically prompt the user to specify which of these groups they are interested in. This iterative selection of cases and prompting for answers from the user avoids the undirected and often fruitless query formation that is a common feature of other approaches [8].
6. Conclusion and Further Work
This paper stresses the growing importance that incident reporting systems have in many safety-critical industries. Unfortunately, many of these schemes currently rely on ad hoc implementations running on relational databases [4]. These systems suffer from a number of problems. Poor precision and low recall may be dismissed as usability issues in other contexts. For safety-critical applications they may prevent analysts from identifying common causes both to software related incidents and other forms of failure. These problems are compounded by the difficulty of query formation in relational systems and by the problems of developing appropriate data models that reflect the ways in which incident reports will change over time. In contrast, information retrieval tools relax many of the problems that frustrate query formation in relational databases but they also make it difficult for users to assess the effectiveness of "naïve" queries. By "naïve" we mean that users may have no understanding of the probabilistic algorithms that determine the precision and recall of their query. Finally, we have proposed conversational case-based reasoning as a means of avoiding these limitations. This approach uses a combination of free-text retrieval techniques together with pre-coded questions to guide a user’s search through increasingly large sets of incident reports. The application of tools, such as the US Navy’s Conversational Decision Aids Environment, can be extended from fault finding tasks to support the retrieval of more general accounts of systems failure, human ‘error’ and managerial ‘weakness’.
It is important to emphasize that more work remains to be done. There are many alternative software-engineering techniques that can be applied to support national and international incident reporting systems. For example, our experience of information retrieval engines is largely based around extensions to Bruce Croft’s Inquery tool [6]. The point of this paper is not, therefore, to advocate the specific algorithms that we have implemented or the systems that we have applied. It is, in contrast, to encourage a greater participation amongst software engineers in the design and maintenance of incident reporting software. If this is not achieved then the world’s leading aircraft manufacturers will continue to have considerable difficulty in searching the incident data that is provided by their customers [4]. If this is not achieved then there will continue to be medical reporting tools that fail to return information about incidents that users know have already been entered into the system [8].
REFERENCES
[1] W. van Vuuren, Organisational Failure: An Exploratory Study in the Steel Industry and the Medical Domain, PhD thesis, Technical University of Eindhoiven, Netherlands, 1998.
[2] D. Busse and C.W. Johnson, Human Error in an Intensive Care Unit: A Cognitive Analysis of Critical Incidents. In J. Dixon (editor) 17th International Systems Safety Conference, Systems Safety Society, Unionville, Virginia, USA, 138-147, 1999.
[3] M.D. Dunlop, C.W. Johnson and J. Reid, Exposing the Layers of Information Retrieval Evaluation, Interacting with Computers, (10)3:225-237, 1998.
[4] S. Lainoff, Finding Human Error Evidence in Ordinary Airline Event Data. In M. Koch and J. Dixon (eds.) 17th International Systems Safety Conference, International Systems Safety Society, Orlando, Florida, 1999.
[5] P. E. Reimers and S. M. Chung, Intelligent User Interface for Very Large Relational Databases. Proc. of the Fifth International Conference on Human-Computer Interaction 1993 v.2 p.134-139
[6] H.R. Turtle and W.B. Croft, Evaluation of an inference network-based retrieval model. ACM Transactions on Information Systems, 9(3):187-222, 1991.
[7] D. Aha, L.A. Breslow and H. Munoz-Avila, Conversational Case-Based Reasoning. Journal of Artificial Intelligence (2000, to appear).
[8] C.W. Johnson, Using Case-Based Reasoning to Support the Indexing and Retrieval of Incident Reports. Accepted and to appear in the Proceedings of European Safety and Reliability Conference (ESREL 2000): Foresight and Precaution, 2000.