 The Multimodal Interaction Group website has moved. Click here to visit the new site
The Multimodal Interaction Group website has moved. Click here to visit the new site
![]()
All about Earcons
Compound earcons
Compound earcons are the simplest of the two types. Compound earcons could be used to represent the actions and objects which make up an interface. They could then be combined in different ways to provide information about any interaction in the interface. If a set of simple, one element motives was created to represent various system elements, for example `create', `destroy, `file' and `string' (see Figure 3.4) these could then be concatenated to form earcons. In the figure the earcon for `create' is a high pitched sound which gets louder, for `destroy' it is a low pitched sound which gets quieter. For `file' there are two long notes which fall in pitch and for `string' two short notes that rise in pitch. In Figure 3.5 the compound earcons can be seen. For the `create file' earcon the `create' motive is simply followed by the `file' motive. This provides a simple and effective method for building up complex messages in sound.
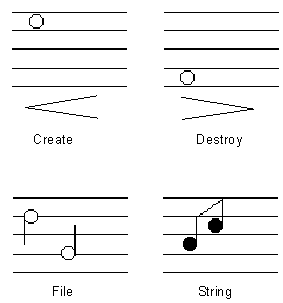
Figure 3.4: The four audio elements `create', `destroy', `file' and `string' (from [25]).
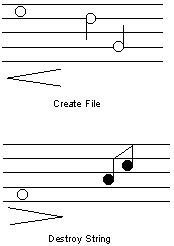
Figure 3.5: Combining audio elements `create file' and `destroy string' (from [25]).
Hierarchical earcons
The second type of audio messages, called family or hierarchical earcons, provide a more powerful, hierarchical system. Each earcon is a node on a tree and inherits all the properties of the earcons above it. Figure 3.6 shows a hierarchy of family earcons. There is a maximum of five levels to the tree as there are only five parameters that can be varied (rhythm, pitch, timbre, register and dynamics). In the diagram the top level of the tree is the family rhythm, in this case it is a sound representing error. This sound just has a rhythm and no pitch, the sounds used are clicks. The rhythmic structure of level one is inherited by level two but this time a second motive is added where pitches are put to the rhythm. At this level, Sumikawa suggests the timbre should be a sine wave, which produces a `colourless' sound. This is done so that at level three the timbre can be varied. At level three the pitch is also raised by a semitone to make it easier to differentiate from the pitches inherited from level two. Other levels can be created where register and dynamics are varied.
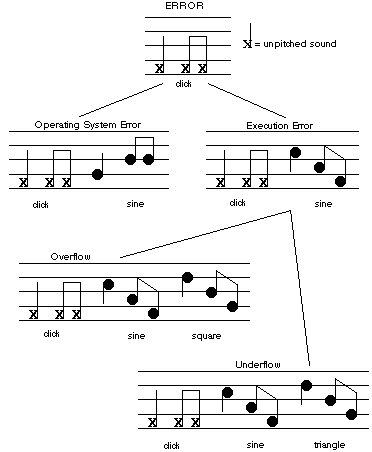
Figure 3.6: A hierarchy of family earcons representing errors (from [25]).
Blattner et al. suggest that for novice users to recognise the sounds, the full earcon at the leaf node of the tree may need to be played (for example, all three motives of the underflow error). Expert users should be able to recognise the earcon if only the last motive was played (just the part labelled triangle in the underflow error). This thesis suggests that, in order for earcons to be useful at the interface, they must be able to keep pace with the interactions going on; if the whole three-motive earcon must be played then they will not be able to keep up. The experiments described in this thesis test hierarchical earcons with just the last motive played to discover their effectiveness.
Learning and remembering earcons
An important factor in the usability of earcons is memorability. If they become too long this may be a problem so Sumikawa suggests they should be kept as short as is necessary to get their message across. Deutsch [49] suggests that structured sequences of tones should be more easily remembered than random tones. The strong rhythmic structure will also aid memory. With the inheritance hierarchy there is only one new piece of information to remember at each level, thus making family earcons easier to remember. Initially, there will be much to learn but later extensions will be simple. For example, if another operating system error was to be added to Figure 3.6 only one new motive would have to be learned in the whole earcon. In systems such as Gaver's auditory icons a whole new sound may have to be learned which is unrelated to any other.Family earcons seem to be a powerful system for representing hierarchical structures such as menus or errors. When navigating through menus the user would normally only be able to see the menu that they were on. Family earcons could provide auditory information about where the user was in the hierarchy without adding to the visual information present. Unfortunately, Blattner et al. did not implement a system of earcons and perform experiments to see how effective they were: Their usefulness is unknown.
The use of the characteristics of sound mentioned above, for example rhythm, pitch, dynamics etc., has a strong psychoacoustic basis. Earcons are based around different rhythms and this is one of the most important methods for grouping sounds into sources (see Chapter 2 on auditory pattern recognition). Sumikawa suggests keeping the notes used from the same octave and in the same scale. This fits in well with the work of Dewar, Cuddy & Mewhort [53] who suggested that listeners can better detect differences between groups of sounds if all the notes in one sound are in a different scale to the other. Keeping all the notes in one octave also minimises pitch perception problems where a listener can mistake the octave to which a note belongs [52]. Loudness perception also plays its part as different loudnesses are used to differentiate earcons. Using the ideas of psychoacoustics two further sound variations could be used to help differentiate earcons from one another. According to the work on auditory pattern recognition, coherence could be used to help group the components of an earcon into a sound source. Modulation could be applied to all the motives of an earcon to cause the separate sounds to be grouped more concretely. Spatial positioning could also be used. Using localisation information to position earcons in different locations in space could also aid grouping of sounds into separate sources (see Moore [118], pp 239-241 for more details).
Earcons have some advantages over auditory icons because they have a strong structure to link them together. This may reduce the learning time and the memory load, but as they have not yet been tested this is unknown. Auditory icons may be more easily recognisable as they are based on natural sounds (which human beings have evolved to listen to over a long period of time) and the sounds contain a semantic link to the objects they represent. Earcons are completely abstract: The sound has no relation to the object that it represents. This may make their association to actions or objects within an interface more difficult. Again, as they have not been tested this is unknown. Cohen [43] pointed out some problems, described above, in that people's intuitive mappings for a sound may be different, and so the meaning of an auditory icon would have to be learned (like an earcon). Problems of ambiguity can occur when natural sounds are taken out of the natural environment: Other cues to help a listener recognise them are lost. If the meanings of auditory icons must be learned then they lose some of their advantages. Earcons have a built-in structure that can easily be manipulated (for example changing pitch or intensity). Auditory icons are only just beginning to get this [76] so that building structures with them at present is difficult. An important step will be to test a system of earcons to discover their advantages and disadvantages. A major part of this thesis is to do just this and find out how effective earcons really are.
Blattner et al. [25] answer one of the questions this thesis is concerned with. They suggest what sounds should be used (earcons) but they do not make any suggestions about where they should be used in the interface. This is investigated as part of the work in this thesis.
Auditory maps and other examples of earcons
There are very few examples of systems using earcons. At the start of the research described in this thesis there were none. The example systems that do currently exist are described in the following section. Blattner, Papp & Glinert [26] added earcons to two-dimensional maps. They used sound (p 459):"...because the addition of visual data requires that space be allocated for it, [and] a saturation point will eventually be reached beyond which interference with text and graphics already on the screen cancels out any possible benefit".
Blattner et al. used a map of floor plans of the Lawrence Livermore National Laboratory. To this they added information in sound such as type of computer equipment contained in the building, security clearance required and jobs of those in the building. Hierarchical earcons were used for the sounds. For example, a three note saxophone earcon indicated an administrative building and a tom-tom represented the security restriction. The faster the tom-tom was played the higher the restriction. The user could click on a building to hear what it contained or they could use an area selector. Any building which was within the area selector would play its earcons, concurrently with the other buildings. This technique allowed much more data to be represented than in the graphical case. Although no experimental testing was reported by Blattner et al. the system seemed to have much potential. A similar approach was also taken by Kramer [104].

Prof Stephen Brewster
Department of Computing Science,
University of Glasgow,
Glasgow, G12 8QQ, UK
Tel: +44 (0)141 330 4966
Fax: +44 (0)141 330 4913
Email: stephen@dcs.gla.ac.uk
Last Modified: 31 October 2002