
Dr. Simon Rogers
School of Computing Science, University of Glasgow
S123, Sir Alwyn Williams Building, G12 8RZ, UK
0141 330 1649

School of Computing Science, University of Glasgow
S123, Sir Alwyn Williams Building, G12 8RZ, UK
0141 330 1649
I'm a senior lecturer in the School of Computing Science at the University of Glasgow. Before starting a permanent post in Glasgow I did a couple of Post Doctoral positions (under Mark Girolami) and prior to that I did my Undergraduate degree (Electrical and Electronic Engineering) and PhD (Machine Learning Techniques for Microarray Analysis, supervisor Colin Campbell) at the University of Bristol.
My research involves the development of Machine Learning and Statistical techniques to help with the analysis of complex datasets, particularly within the field of Metabolomics but also other -omics fields, Human-Computer Interaction and Information Retreival. My Metabolomics work is done in collaboration with many people, particularly Glasgow Polyomics (of which I'm an affiliate member).
In 2011, Mark Girolami and I published a textbook: A First Course in Machine Learning which you might find useful if you want an introduction to modern (fairly probabilistic) Machine Learning but don't know a great deal of maths. A second edition with additional material (Gaussian Processes, Dirichlet Processes, was published in August 2016.
I am always interested in hearing from potential PhD candidates. If any of the research below interests you, please get in touch. If you want to find my office, there are some instructions below.
I vary rarely blog, but when I do it is at sirogers.wordpress.com. You can find me on github as sdrogers, my orcid is orcid.org/0000-0003-3578-4477 and if you like Google Scholar, I'm here.
I review for many journals and conferences, as well as being an associate editor for PLoS One. I have acted as an internal and external examiner for several PhD theses (in the UK and abroad) and am currently one of the external examiners for the computing science taught masters programmes at the University of Manchester.
I currently hold various non-research roles within the School of Computing Science: Graduate School Convenor (aka PG tutor), deputy senior adviser of studies and I'm a member of the College of Science and Engineering's appeals committee. I played a substantial role in the successful Athena Swan bronze application made by the School.
A full list of publications is available at Glasgow Universities online repository, Enlighten. You can also find a large selection of my publications on orcid, as well as a list of funding (my ID is 0000-0003-3578-4477), or Google Scholar. If you would like copies of anything, email me.
Latest News: MS2LDA+ is now published in Analytical Chemistry
Latest News: Our recent work on the application of text modelling methods to metabolite fragment data has been published in PNAS: Topic modeling for untargeted substructure exploration in metabolomics. We are currently developing an web application to explore the results of this type of analysis: ms2lda.org
My main research activities are in the application of machine learning and applied statistical techniques to problems in metabolomics. Metabolomics is the study of the small molecule content of an organism and I'm particularly interested in the analysis of mass spectrometry metabolomics data. Mass Spectrometry allows, in theory, the simultanoues measurement of the abundance of many metabolites but use of this technology is hindered by the difficuly in analysising the data, particularly in identifying the molecules present in the data from the measured masses.
Some notable contributions in this area include a method for using the dependencies between metabolites to aid in identification, a probabilistic method for metabolite annotation / identification, and the use of peak groupe to improve alignment and differential expression computation.
Currently, I'm working on novel ways of analysing molecular fragmentation data.
Much of this work is done in collaboration with Glasgow Polyomics, of which I'm an affiliate member.
Microarray analysis: The research in my PhD centered around developing Machine Learning techniques to analyse data from cDNA microarrays, including a 2003 paper on the number of arrays needed to be able to classify diseased from healthy samples which is still being cited. I also performed one of the first analyses on combine time series transcriptomic and proteomic data.
Parameter inference: I am currently involved in an EPSRC funded project (EP/L020319/1) on parameter inference in mechanistic models of biological systems (with Dirk Husmeier and Maurizio Filippone) where we are interested in using gradient matching to speed up inference in systems of ordinary differential equations (ICML 2016) as well as a BBSRC funded project (BB/L001276/1) on stomatal dynamics with Mike Blatt (plant sciences, Glasgow) and others.
Leaukaemia: I co-supervise two PhD students who are using bioinformatics tools to help learn about Chronic Myeloid Leukaemia, with Prof. Tessa Holyoake.
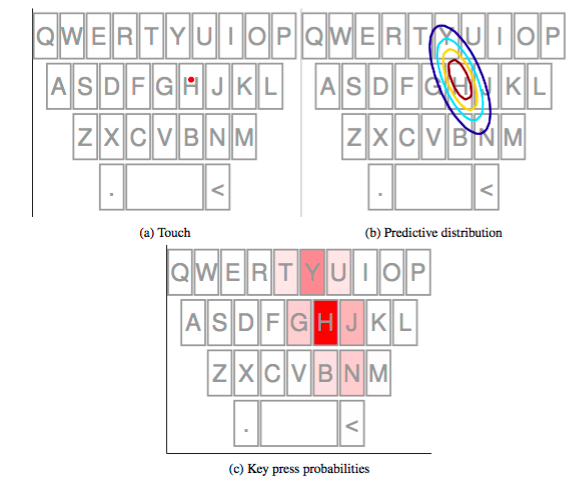
I'm interested in how we can better model the uncertainty in user interactions with a goal towards making better systems. This work began with the work on FingerCloud, which used a particle filter to model the position of the finger in 3D above an array of capacitive sensors. This filter was used to control a map, where the less engaged the user was the more autonomous the map became. We extended this to AnglePose which inferred the pitch and yaw angles of the interacting finger, along with its position. This work was taken forward in Daryl Weir's PhD in which he looked at modelling uncertainty in touch. This started with a UIST paper that used Machine Learning to learn offset models for specific users and ended with a CHI paper demonstrating a keyboard that used both the learned offset and variability for specific users to improve typing performance. The offset work was built upon by Daniel Buschek, who published an interesting study in MobileHCI investigating how offset patterns varied across users and varied for the same user on different devices.
With John Williamson, I have been co-supervising Faizuddin M.Noor's PhD on using back of device sensors for implicit interactions. We have shown that it is possible to detect where a user is going to touch a screen before they do so (CHI 2014) and, more recently showed that it is possible to detect user errors due to hand movement and changes in their grip patterns (CHI 2016).
Information Retreival: Along with Iadh Ounis, I supervised Edwin Thuma's PhD on A semi-automated FAQ retrieval system for HIV/AIDS. Edwin built a system to which users could send an SMS including questions about HIV/AIDS that would attempt to send an answer from a FAQ handbook used by the department of health in Botswana. There were three publications arising from this thesis: Exploiting query logs and field-based models..., Detecting missing content queries..., and Evaluating bad query abandonment...
Robotics: With Paul Siebert, I currently supervise Li Sun's PhD on using a robot to manipulate clothing.
Code and data for older work can be found at the following links:
Lorna Jackson
Eduardo Gómez Castañeda
Dr. Faizuddin M. Noor Machine learning techniques for implicit interaction using mobile sensors
Interactions in mobile devices normally happen in an explicit manner, which means that they are initiated by the users. Yet, users are typically unaware that they also interact implicitly with their devices. For instance, our hand pose changes naturally when we type text messages. Whilst the touchscreen captures finger touches, hand movements during this interaction however are unused. If this implicit hand movement is observed, it can be used as additional information to support or to enhance the users’ text entry experience. This thesis investigates how implicit sensing can be used to improve existing, standard interaction technique qualities. In particular, this thesis looks into enhancing front-of-device interaction through back-of-device and hand movement implicit sensing. We propose the investigation through machine learning techniques. We look into problems on how sensor data via implicit sensing can be used to predict a certain aspect of an interaction. For instance, one of the questions that this thesis attempts to answer is whether hand movement during a touch targeting task correlates with the touch position. This is a complex relationship to understand but can be best explained through machine learning. Using machine learning as a tool, such correlation can be measured, quantified, understood and used to make predictions on future touch position. Furthermore, this thesis also evaluates the predictive power of the sensor data. We show this through a number of studies. In Chapter 5 we show that probabilistic modelling of sensor inputs and recorded touch locations can be used to predict the general area of future touches on touchscreen. In Chapter 7, using SVM classifiers, we show that data from implicit sensing from general mobile interactions is user-specific. This can be used to identify users implicitly. In Chapter 6, we also show that touch interaction errors can be detected from sensor data. In our experiment, we show that there are sufficient distinguishable patterns between normal interaction signals and signals that are strongly correlated with interaction error. In all studies, we show that performance gain can be achieved by combining sensor inputs.
Dr. Joe Wandy Bayesian methods for metabolomics
Abstract to appear
Dr. Daryl Weir Modelling Uncertainity in Touch Interactions
Touch interaction is an increasingly ubiquitous input modality on modern devices. It appears on devices including phones, tablets, smartwatches and even some recent laptops. Despite its popularity, touch as an input technology suffers from a high level of measurement uncertainty. This stems from issues such as the ‘fat finger problem’, where the soft pad of the finger creates an ambiguous contact region with the screen that must be approximated by a single touch point. In addition to these physical uncertainties, there are issues of uncertainty of intent when the user is unsure of the goal of a touch. Perhaps the most common example is when typing a word, the user may be unsure of the spelling leading to touches on the wrong keys. The uncertainty of touch leads to an offset between the user’s intended target and the touch position recorded by the device. While numerous models have been proposed to model and correct for these offsets, existing techniques in general have assumed that the offset is a deterministic function of the input. We observe that this is not the case — touch also exhibits a random component. We propose in this dissertation that this property makes touch an excellent target for analysis using probabilistic techniques from machine learning. These techniques allow us to quantify the uncertainty expressed by a given touch, and the core assertion of our work is that this allows useful improvements to touch interaction to be obtained. We show this through a number of studies. In Chapter 4, we apply Gaussian Process regression to the touch offset problem, producing models which allow very accurate selection of small targets. In the process, we observe that offsets are both highly non-linear and highly user-specific. In Chapter 5, we make use of the predictive uncertainty of the GP model when applied to a soft keyboard — this allows us to obtain key press probabilities which we combine with a language model to perform autocorrection. In Chapter 6, we introduce an extension to this framework in which users are given direct control over the level of uncertainty they express. We show that not only can users control such a system succesfully, they can use it to improve their performance when typing words not known to the language model. Finally, in Chapter 7 we show that users’ touch behaviour is significantly different across different tasks, particularly for typing compared to pointing tasks. We use this to motivate an investigation of the use of a sparse regression algorithm, the Relevance Vector Machine, to train offset models using small amounts of data.
Dr. Rebecca Mancy Modelling persistence in spatially-explicit ecological and epidemiological systems
In this thesis, we consider the problem of long-term persistence in ecological and epidemiological systems. This is important in conservation biology for protecting species at risk of extinction and in epidemiology for reducing disease prevalence and working towards elimination. Understanding how to predict and control persistence is critical for these aims. In Chapter 2, we discuss existing ways of characterising persistence and their relationship with the modelling paradigms employed in ecology and epidemiology. We note that data are often limited to information on the state of particular patches or populations and are modelled using a metapopulation approach. In Chapter 3, we define persistence in relation to a pre-specified time horizon in stochastic single-species and two-species competition models, comparing results between discrete and continuous time simulations. We find that discrete and continuous time simulations can result in different persistence predictions, especially in the case of inter-specific competition. The study also serves to illustrate the shortcomings of defining persistence in relation to a specific time horizon. A more mathematically rigorous interpretation of persistence in stochastic models can be found by considering the quasi-stationary distribution (QSD) and the associated measure of mean time to extinction from quasi-stationarity. In Chapter 4, we investigate the contribution of individual patches to extinction times and metapopulation size, and provide predictors of patch value that can be calculated easily from readily available data. In Chapter 5, we focus directly on the QSD of heterogeneous systems. Through simulation, we investigate possible compressions of the QSD that could be used when standard numerical approaches fail due to high system dimensionality, and provide guidance on appropriate compression choices for different purposes. In Chapter 6, we consider deterministic models and investigate the effect of introducing additional patch states on the persistence threshold. We suggest a possible model that might be appropriate for making predictions that extend to stochastic systems. By considering a family of models as limiting cases of a more general model, we demonstrate a novel approach for deriving quantities of interest for linked models that should help guide modelling decisions. Finally, in Chapter 7, we draw out implications for conservation biology and disease control, as well as for future work on biological persistence.
Dr. Edwin Thuma A semi-automated FAQ retrieval system for HIV/AIDS
This thesis describes a semi-automated FAQ retrieval system that can be queried by users through short text messages on low-end mobile phones to provide answers on HIV/AIDS related queries. First we address the issue of result presentation on low-end mobile phones by proposing an iterative interaction retrieval strategy where the user engages with the FAQ retrieval system in the question answering process. At each iteration, the system returns only one question-answer pair to the user and the iterative process terminates after the user's information need has been satisfied. Since the proposed system is iterative, this thesis attempts to reduce the number of iterations (search length) between the users and the system so that users do not abandon the search process before their information need has been satisfied. Moreover, we conducted a user study to determine the number of iterations that users are willing to tolerate before abandoning the iterative search process. We subsequently used the bad abandonment statistics from this study to develop an evaluation measure for estimating the probability that any random user will be satisfied when using our FAQ retrieval system. In addition, we used a query log and its click-through data to address three main FAQ document collection deficiency problems in order to improve the retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system. Conclusions are derived concerning whether we can reduce the rate at which users abandon their search before their information need has been satisfied by using information from previous searches to: Address the term mismatch problem between the users' SMS queries and the relevant FAQ documents in the collection; to selectively rank the FAQ document according to how often they have been previously identified as relevant by users for a particular query term; and to identify those queries that do not have a relevant FAQ document in the collection. In particular, we proposed a novel template-based approach that uses queries from a query log for which the true relevant FAQ documents are known to enrich the FAQ documents with additional terms in order to alleviate the term mismatch problem. These terms are added as a separate field in a field-based model using two different proposed enrichment strategies, namely the Term Frequency and the Term Occurrence strategies. This thesis thoroughly investigates the effectiveness of the aforementioned FAQ document enrichment strategies using three different field-based models. Our findings suggest that we can improve the overall recall and the probability that any random user will be satisfied by enriching the FAQ documents with additional terms from queries in our query log. Moreover, our investigation suggests that it is important to use an FAQ document enrichment strategy that takes into consideration the number of times a term occurs in the query when enriching the FAQ documents. We subsequently show that our proposed enrichment approach for alleviating the term mismatch problem generalise well on other datasets. Through the evaluation of our proposed approach for selectively ranking the FAQ documents, we show that we can improve the retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system by incorporating the click popularity score of a query term t on an FAQ document d into the scoring and ranking process. Our results generalised well on a new dataset. However, when we deploy the click popularity score of a query term t on an FAQ document d on an enriched FAQ document collection, we saw a decrease in the retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system. Furthermore, we used our query log to build a binary classifier for detecting those queries that do not have a relevant FAQ document in the collection (Missing Content Queries (MCQs))). Before building such a classifier, we empirically evaluated several feature sets in order to determine the best combination of features for building a model that yields the best classification accuracy in identifying the MCQs and the non-MCQs. Using a different dataset, we show that we can improve the overall retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system by deploying a MCQs detection subsystem in our FAQ retrieval system to filter out the MCQs. Finally, this thesis demonstrates that correcting spelling errors can help improve the retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system. We tested our FAQ retrieval system with two different testing sets, one containing the original SMS queries and the other containing the SMS queries which were manually corrected for spelling errors. Our results show a significant improvement in the retrieval performance and the probability that any random user will be satisfied when using our FAQ retrieval system.
Dr. Mikhail Churakov Spatial and network aspects of the spread of infectious diseases in livestock populations
In this thesis, I focus on methodological concepts of studying infectious disease transmission between agricultural premises. I used different disease systems as exemplars for spatial and network methods to investigate transmission patterns. Infectious diseases cause tangible economic threat to the farming industry worldwide by damaging livestock populations, reducing farm productivity and causing trade restriction. This implies the importance of veterinary epidemiological studies in control and eradication of pathogens. Recent increase in availability of data and computational power allowed for more opportunities to study mechanisms of pathogenic transmission. Nowadays, the bottleneck is primarily associated with efficient methods that can analyse vast amounts of high-resolution data. Here I address two livestock pathogens that differ in their epidemiology: bacteria Streptococcus agalactiae and foot-and-mouth disease (FMD) virus. Streptococcus agalactiae is a contagious pathogen that causes mastitis in cattle, and thus possesses a substantial economic burden to the dairy industry. Known transmission routes between cattle are restricted to those via milking machines, milkers’ hands and fomites during milking process. Additionally, recent studies suggested potential introductions from other host species: primarily, humans. However, strain typing data showed discrepancies in strain compositions of bacteria isolated from humans and bovines. In this thesis, strain-specific features of between-herd transmission of Streptococcus agalactiae within dairy cattle population in Denmark are investigated. Foot-and-mouth disease (FMD) is a viral infection that affects cloven-hoofed animals and is of big importance mainly because of the trade restrictions against infected regions and countries. Control programmes against FMD usually include vaccination and culling of animals. However, the debate on the optimal control for FMD is still ongoing. In this thesis, I address questions on identification of the routes of infection and on requirements for movement recording systems to be used for efficient contact tracing during an FMD outbreak. This thesis reveals several interesting findings. Firstly, the increased understanding of strain-specific transmission characteristics of Streptococcus agalactiae. One of the observed strains (ST103) showed significant and consistent spatial clustering of its cases among Danish dairy cattle herds in 2009–2011. Secondly, the network analysis of cattle movements and affiliations with veterinary practices showed that veterinary practices were exclusively associated with transmission of ST103 of Streptococcus agalactiae. Contrastingly, movement networks appeared to be important for all the three predominant bacterial strains (ST1, ST23 and ST103). Fourthly, the new extended approach that allows estimation of the whole transmission tree at once was proposed and tested for the Darlington cluster within the 2001 FMD UK epidemic. Finally, in chapter 6, it was shown that mathematical modelling did not suggest any advantages of ensuring smaller delays in the post-silent control of FMD-like pathogens.
Dr. Li (Kevin) Sun Integrated visual perception architecture for robotic clothes perception and manipulation
This thesis proposes a generic visual perception architecture for robotic clothes perception and manipulation. This proposed architecture is fully integrated with a stereo vision system and a dual-arm robot and is able to perform a number of autonomous laundering tasks. Clothes perception and manipulation is a novel research topic in robotics and has experienced rapid development in recent years. Compared to the task of perceiving and manipulating rigid objects, clothes perception and manipulation poses a greater challenge. This can be attributed to two reasons: firstly, deformable clothing requires precise (high-acuity) visual perception and dexterous manipulation; secondly, as clothing approximates a non-rigid 2-manifold in 3-space, that can adopt a quasi-infinite configuration space, the potential variability in the appearance of clothing items makes them difficult to understand, identify uniquely, and interact with by machine. From an applications perspective, and as part of EU CloPeMa project, the integrated visual perception architecture refines a pre-existing clothing manipulation pipeline by completing pre-wash clothes (category) sorting (using single-shot or interactive perception for garment categorisation and manipulation) and post-wash dual-arm flattening. To the best of the author’s knowledge, as investigated in this thesis, the autonomous clothing perception and manipulation solutions presented here were first proposed and reported by the author. All of the reported robot demonstrations in this work follow a perception-manipulation method- ology where visual and tactile feedback (in the form of surface wrinkledness captured by the high accuracy depth sensor i.e. CloPeMa stereo head or the predictive confidence modelled by Gaussian Processing) serve as the halting criteria in the flattening and sorting tasks, respectively. From scientific perspective, the proposed visual perception architecture addresses the above challenges by parsing and grouping 3D clothing configurations hierarchically from low-level curvatures, through mid-level surface shape representations (providing topological descriptions and 3D texture representations), to high-level semantic structures and statistical descriptions. A range of visual features such as Shape Index, Surface Topologies Analysis and Local Binary Patterns have been adapted within this work to parse clothing surfaces and textures and several novel features have been devised, including B-Spline Patches with Locality-Constrained Linear coding, and Topology Spatial Distance to describe and quantify generic landmarks (wrinkles and folds). The essence of this proposed architecture comprises 3D generic surface parsing and interpretation, which is critical to underpinning a number of laundering tasks and has the potential to be extended to other rigid and non-rigid object perception and manipulation tasks. The experimental results presented in this thesis demonstrate that: firstly, the proposed grasp- ing approach achieves on-average 84.7% accuracy; secondly, the proposed flattening approach is able to flatten towels, t-shirts and pants (shorts) within 9 iterations on-average; thirdly, the proposed clothes recognition pipeline can recognise clothes categories from highly wrinkled configurations and advances the state-of-the-art by 36% in terms of classification accuracy, achieving an 83.2% true-positive classification rate when discriminating between five categories of clothes; finally the Gaussian Process based interactive perception approach exhibits a substantial improvement over single-shot perception. Accordingly, this thesis has advanced the state-of-the-art of robot clothes perception and manipulation.
Machine Learning 4/M - Moodle
Advanced Programming (IT) - Moodle
S1 Systems Biology lectures - Material
I've supervised projects in many areas and I'm happy to discuss opportunities in any area broadly related to my research interests. I'm currently particularly interested in projects in computational metabolomics, ranging from software engineering projects to more open ended research ones. If you would like to see projects from previous years, here are some (email me if you would like one that isn't listed):

This introductory level textbook was developed from a Machine Learning course delivered at the University of Glasgow initially by Mark Girolami and then taken over by me. As the course was aimed at final year Computing Science students who may not have taken any courses in statistics or mathematics, the book assumes almost no pre-requisites in mathematics or statistics.
More details can be found on the book webpage here.
It is available direct from the publishers, Chapman and Hall / CRC or from Amazon UK or Amazon US.
The second edition was published in August 2016. This new edition includes three new chapters (>100 pages of new material) that covers some advanced topics: Gaussian Processes, Markov Chain Monte Carlo Sampling, and Dirichlet Processes. When you buy the hard copy you get the e-book version included.

From the foyer of the Sir Alwyn Williams Building (see map on right), either take the stairs to floor 'S' or take the lift to the second floor (use the left hand button; we have two second floors).
Once on floor 'S', walk along the corridor for about 50m until you come to S123 on the right.
If you get lost, return to the foyer and ring me using the phone there on extension 1649.